
String
String은 각각의 문자를 나열한 배열을 나타내는 객체입니다. Java에서 제공하는 Primitive Type(원시 타입)을 제외한 모든 나머지들은 객체로 구성되어 있으며 객체 생성은 생성자(construct)를 통해 이루어집니다. 하지만 String은 객체를 생성할 때 생성자를 사용하는 방법 외에도 바로 값을 할당하여 생성할 수 있는데 이를 문자열 리터럴(String Literal)이라 부릅니다.
1
2
3
4
public static void main(String[] args) {
String str1 = new String("a"); // 생성자
String str2 = "a"; // 문자열 리터럴
}
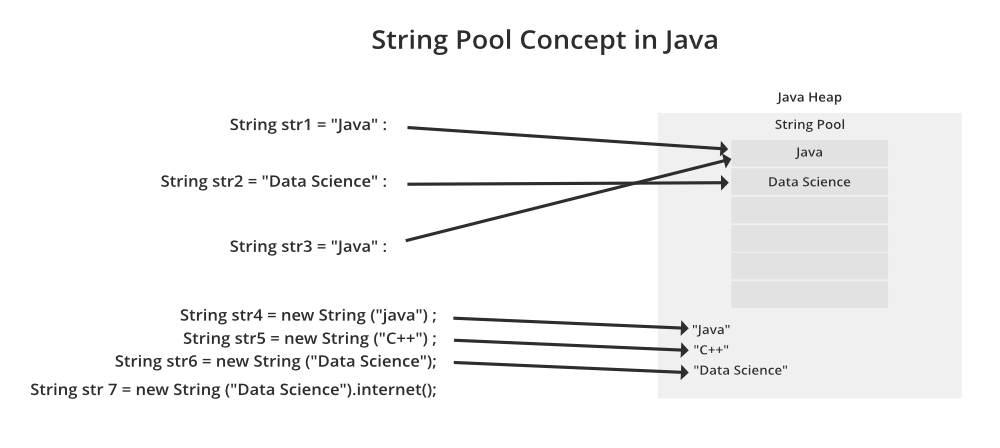
String은 위와 같이 두가지 방법으로 객체를 생성할 수 있습니다. 첫번째 방법은 일반적으로 객체를 생성하는 방법인 생성자를 사용하는 방법이며 두번째 방법이 문자열 리터럴을 사용해 객체를 생성하는 방법입니다. 두 변수에는 동일안 'a'라는 값을 가지고 있는 객체이지만, 객체가 할당되는 메모리 영역에는 차이가 있습니다. Java에서 동적으로 객체를 생성하게 되면 객체(참조값)를 메모리에 저장하게 되는데 자바의 메모리는 이를 모든 스레드에서 접근 가능한 Heap 영역에 할당하게 됩니다. 하지만 문자열 리터럴로 생성한 객체는 String Constant Pool 라는 특별한 영역에 할당하여 관리하게 됩니다.
String Constant Pool
String Constant Pool은 자바의 문자열 상수를 관리하기 위해 사용되는 특별한 메모리 영역입니다. 내부적으로 각 String Constant를 hashing하여 key로 value를 조회하기때문에 탐색에서 좋은 성능을 보여줍니다. 과거 버전 Java의 String Constant Pool은 Permenent Generation에 있어 고정된 크기의 저장 공간이였기 때문에 OOM(OutOfMemory) 제약이 있었지만, 버전이 업그레이드 되면서 위치가 Heap 영역에서 Metaspace 영역으로 이동됐습니다.
Metaspace 영역은 JVM의 Native Memory를 사용하며 JVM이 관리합니다. Permenent Generation 영역과의 결정적인 차이는 메모리가 동적으로 관리되며 필요할 경우 OS에게 요청하여 메모리를 추가 할당할 수 있습니다.
- Java 6 이전: String Constant Pool은 클래스와 관련된 메타 데이터를 저장하는 JVM의 메모리 영역의 Permanent Generation 저장되었습니다.
- Java 7: Permanent Generation이 아닌 Heap 영역에 저장하면서 메모리 관리 측면에서 유연성을 높혔습니다.
- Java 8: Permanent Generation가 완전히 제거되었고, 네이티브 메모리 영역인 Metaspace라는 새로운 메모리 영역이 도입되면서 String Constant Pool은 Metaspace에 저장됩니다. 또한 8버전을 기점으로 내부 구현도 HashTable에서 HashMap으로 변경됐습니다.
- Java 9 이후: UTF-16이 아닌 바이트 배열로 문자열을 저장하는 Compact Strings라는 새로운 구현이 도입되었습니다.
Permenent Generation 영역은 고정된 사이즈이기 때문에 Runtime 시점에 사이즈를 확장할 수 없습니다. 7 버전에서 Heap 영역으로 이동시킴으로써 GC의 대상으로 될 수 있는 이점을 얻습니다. 하지만 8버전부터 Metaspace 영역으로 이동되면서 GC의 관리 대상에서 벗어났지만, 문자열 참조 대상이 없는 경우 선택적으로 GC 대상이 되기도합니다. 또한,
-XX:+UseStringDeduplication옵션 사용을 통해 중복 문자열에 대해 GC를 수행하도록 트리거를 줄 수 있습니다. 자세한 내용은 이곳에서 확인할 수 있습니다.
또한 동적으로 생성되는 문자열의 경우에는 String Constant Pool에 저장되는 대상이 아닙니다. 그러므로 이런 동적인 문자열은 동등성(equals) 비교를 해야합니다.
Compact Strings
Java 8 버전 이전까지는 String 객체 내부적으로 UTF-16으로 인코딩된 문자 배열(char[])을 사용했지만, Java 9 버전부터는 Compact Strings를 제공함으로써 문자열의 압축 여부에 따라 문자열 배열과 바이트 배열를 선택하여 인코딩합니다. 때문에 사용하는 문자열(언어)별로 1 바이트, 2 바이트 메모리를 동적으로 할당할 수 있게 됐습니다. 이로써 Heap 메모리 사용량을 줄여 GC(Garvage Collector) 오버헤드(overhead)가 줄어드는 효과를 얻습니다.
Intern
1
2
3
4
5
6
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
...
public native String intern();
...
}
intern() 메소드는 String Constant Pool에 해당 문자열이 있는지 equals() 메소드를 통해 판별하고 없으면 상수 풀에 저장한 후 참조값을 전달하고, 있으면 기존 Pool에 있는 참조 값을 넘겨줍니다. 해당 메소드는 강제로 String Constant Pool에 넣기 때문에 동적으로 생성되는 문자열에 intern() 메소드를 사용하게 된다면 OOM(OutOfMemory) 에러가 발생합니다. 즉, 메모리 누수 발생 가능성을 높이는 메소드이므로 사용에 주의를 필요로합니다.
Immutability
String은 객체로 생성된 후 상태를 변경할 수 없는 불변(Immutable) 객체입니다. 다음과 같은 이유로 불변 객체로 설계되었습니다.
- 스레드 안전성: 객체가 불변하면 여러 스레드에서 동시에 접근해도 변경할 필요가 없기 때문에 동기화가 필요하지 않습니다. 이는 멀티스레드 환경에서 안전하게 사용할 수 있습니다.
- 보안성: 문자열은 많은 애플리케이션에서 중요한 데이터를 나타내는 경우가 많습니다. 문자열을 불변으로 설계하면 다른 객체에서 문자열을 변경할 수 없으므로, 악의적인 변경을 방지하고 데이터 무결성을 보장할 수 있습니다.
- 메모리 최적화: 불변 객체는 생성 후 변경이 불가능하므로, 한 번 생성된 객체는 재사용될 수 있습니다.
- 캐시와 문자열 연산 최적화: 불변 문자열은 문자열 연산 시에 캐시로 활용될 수 있습니다. 예를 들어, 문자열 연결 연산에서 이미 생성된 문자열을 재사용하여 연산 속도를 향상시킬 수 있습니다.
Construct VS Literal
생성자를 통해 객체를 생성하면 일반적인 객체와 같이 Heap 영역에 새로운 객체를 생성하여 저장합니다. 하지만 리터럴을 사용하여 객체를 생성하는 경우, 해당 문자열은 String Constant Pool에 저장이 되고 이미 존재하는 문자열이라면 기존에 생성한 객체를 반환합니다. 때문에 특별한 경우가 아니라면 생성자를 통한 생성은 지양해야합니다.
StringBuilder & StringBuffer
String은 불변 객체로 한번 할당된 후 변경할 수 없기 때문에, 다른 값에 대한 연산에는 많은 시간과 자원을 사용한다는 단점이 있습니다.
예를 들어 단지 값을 추가하는 코드지만 실제로는 서로 다른 참조값을 가지는 2개의 객체가 생성이됩니다.
1
2
3
4
5
6
public static void main(String[] args) {
String str1 = "a";
String str2 = "a" + "b";
System.out.println(str1 == str2); // false
}
추가로 덧셈(+) 연산자를 통해 문자열을 결합한다는 것 또한 새로운 String 객체를 생성하게 되어 많은 자원을 사용하기 때문에 속도가 느려지는 단점이 있습니다.
1
2
3
4
5
public static void main(String[] args) {
String str1 = "a";
str1 += "b";
str1 += "c";
}
이런 문제점들을 해결하기 위해 문자열 연산에 특화된 기능을 제공하는 StringBuilder 와 StringBuffer가 등장하게 되었습니다. 이 둘은 가변(mutable)하는 문자열을 처리하기 위한 클래스로 불변 객체인 String을 문자열 추가, 수정, 삭제 등 동적으로 조작할 수 있는 메소드드를 제공합니다.
AbstractStringBuilder
AbstractStringBuilder는 StringBuilder 와 StringBuffer의 핵심 기능을 추상화한 클래스로, 문자열 조작에 필요한 기본적인 동작과 메소드를 제공합니다. 동작 방식을 알아보기 전에 AbstractStringBuilder이 가지고 있는 맴버 변수로 3가지를 살펴봐야 합니다.
- byte[] value: 문자열을 저장하기 위한 바이트 배열
- int count: 사용된 문자의 갯수
- byte coder: 값(value)의 인코딩 식별자
value는 바이트 배열로 객체 내부에서 버퍼(buffer)로 사용되는 문자열 데이터를 관리하고 조작하는데 사용됩니다.
count는 문자열의 용량(capacity)을 관리하기 위한 문자열 데이터의 길이로 내부 버퍼의 크기를 나타내며, 현재 관리 중인 문자열 데이터의 길이만큼 늘어납니다.
coder는 Java 11부터 추가된 맴버 변수로 이는 인코딩 값에 따라 단일 바이트 또는 2 바이트로 처리하기 위한 문자열 데이터의 인코딩 식별자를 나타내기 위한 변수입니다.
위와 같이 3개의 맴버 변수를 가지고 있으며 AbstractStringBuilder가 해당 변수를 어떤 식으로 관리하고 활용하는지 생성 시점부터 문자열 데이터를 조작하는 주요 메소드를 통해 살펴 보겠습니다.
Constructor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private static final byte[] EMPTYVALUE = new byte[0];
AbstractStringBuilder() {
value = EMPTYVALUE;
}
AbstractStringBuilder(int capacity) {
if (COMPACT_STRINGS) {
value = new byte[capacity];
coder = LATIN1;
} else {
value = StringUTF16.newBytesFor(capacity);
coder = UTF16;
}
}
AbstractStringBuilder는 기본 생성자와 int를 매개 변수로 가지는 2가지의 생성자를 제공합니다. 기본 생성자는 관리할 문자열 데이터를 가지고 있지 않기 때문에 빈 바이트 배열을 버퍼에 할당하게 됩니다.
매개 변수로 용량(capacity)을 받는 생성자는 COMPACT_STRINGS의 활성화 여부에 따라 문자열 데이터에 사용할 인코딩을 설정합니다.
기본적으로
COMPACT_STRINGS는 비활성화 되어 있지만 JVM 플래그를 통해 활성화 할 수 있습니다.java -XX:+CompactStrings ${APP_NAME}
COMPACT_STRINGS가 활성화 되어 있다면 문자열 데이터를 단일 바이트로 처리하기 위한 인코딩으로 LATIN1이 설정됩니다. 비활성화 상태라면 UTF-16 문자열 데이터를 2 바이트 처리하는 인코딩으로 설정됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
final class StringUTF16 {
public static byte[] newBytesFor(int len) {
if (len < 0) {
throw new NegativeArraySizeException();
}
if (len > MAX_LENGTH) {
throw new OutOfMemoryError("UTF16 String size is " + len +
", should be less than " + MAX_LENGTH);
}
return new byte[len << 1];
}
...
}
2 바이트로 데이터를 처리하기 위해서는 관리하는 버퍼의 용량을 늘려야하기 때문에 StringUTF16.newBytesFor() 메소드를 호출하여 전달받은 용량을 \(2^1\) 만큼 Left Shift 시킵니다.
append
1
2
3
4
5
6
7
8
9
10
public AbstractStringBuilder append(String str) {
if (str == null) {
return appendNull();
}
int len = str.length();
ensureCapacityInternal(count + len);
putStringAt(count, str);
count += len;
return this;
}
인자로 넘어온 값이 null일 경우 appendNull() 메소드 실행 후 종료합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private AbstractStringBuilder appendNull() {
ensureCapacityInternal(count + 4);
int count = this.count;
byte[] val = this.value;
if (isLatin1()) {
val[count++] = 'n';
val[count++] = 'u';
val[count++] = 'l';
val[count++] = 'l';
} else {
count = StringUTF16.putCharsAt(val, count, 'n', 'u', 'l', 'l');
}
this.count = count;
return this;
}
null 값이면 현재 문자열 데이터의 인코딩에 맞는 용량만큼 증가시키고 문자열 “null”을 현재 문자열 데이터 끝 부분에 추가합니다. 또한 문자열 데이터에 값이 추가됨에 따라 내부 버퍼의 용량을 확보하기 위해 파라미터의 길이만큼 필요한 용량을 증가 시키기 위해 ensureCapacityInternal() 메소드를 호출합니다.
1
2
3
4
5
6
7
8
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
int oldCapacity = value.length >> coder;
if (minimumCapacity - oldCapacity > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity) << coder);
}
}
먼저 현재 내부 버퍼의 용량인 oldCapacity를 계산합니다. 문자열 데이터의 인코딩을 나타내는 coder는 단일 바이트 또는 2 바이트이며 현재 내부 버퍼의 길이에 Right Shift하게 됩니다. minimumCapacity - oldCapacity가 양수라면, 즉 내부 버퍼 용량을 확보해야한다면 현재 인코딩에 맞춰 새로운 용량으로 복사하여 재할당합니다.
충분한 버퍼 용량이 확보됐다면 실제 버퍼에 추가된 문자열을 추가하는 putStringAt()메소드를 호출합니다.
1
2
3
4
5
6
private final void putStringAt(int index, String str) {
if (getCoder() != str.coder()) {
inflate();
}
str.getBytes(value, index, coder);
}
현재 내부 버퍼의 문자열 데이터와 인자로 넘어온 문자열의 인코딩이 각각 다른 경우 먼저 인코딩 방식을 조정하기 위해 내부 버퍼 용량을 확보하는 inflate() 메소드를 실행 시킵니다. 내부 버퍼가 충분히 확보 되었다면 내부 버퍼에 지정된 인덱스, 즉 현재 문자열 데이터 끝 부분부터 인자로 넘어온 문자열을 삽입합니다.
그 후 버퍼 용량을 나타내는 맴버 변수 count를 인자로 넘어온 문자열 길이를 더해줌으로써 메소드는 종료됩니다.
마지막으로 append() 메소드를 정리하자면 아래와 같습니다.
- 현재 버퍼에 존재하는 문자열 데이터에 지정된 문자열을 추가합니다.
- 문자열 인자의 문자들이 순서대로 추가되며, 인자의 길이만큼 이 시퀀스의 길이가 증가합니다.
- 인자가
null인 경우, “null”이라는 4개의 문자가 추가됩니다.
StringBuilder 와 StringBuffer의 차이점
StringBuilder 와 StringBuffer 모두 AbstractStringBuilder라는 추상 클래스를 상속 받아 이미 구현된 핵심 기능을 사용하고 있습니다. 하지만 단 한가지 차이점이 존재한다면, 스레드 안전성입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuilder>, CharSequence
{
...
@Override
@HotSpotIntrinsicCandidate
public StringBuilder append(String str) {
super.append(str);
return this;
}
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuffer>, CharSequence
{
...
@Override
@HotSpotIntrinsicCandidate
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
...
}
위 코드 블럭은 StringBuilder 와 StringBuffer의 append() 메소드 부분만 가져온 부분입니다. 두 클래스 모두 AbstractStringBuilder.append()를 호출하지만 StringBuffer는 synchronized 자바 예약어 명시를 통해 스레드간 동기화를 보장하는 것이 차이입니다. StringBuffer는 멀티 스레드 환경에서 한 스레드가 해당 append()를 수행하고 있다면, 수행 중인 스레드에 lock을 걸어 스레드 안전성을 보장합니다. 정리하자면 두 클래스는 문법이나 내부 구현도 모두 같지만, 동기화 지원 유무에서 차이가 있습니다. StringBuilder는 동기화를 지원하지 않는 반면 StringBuffer를 지원하여 멀티 스레드 환경에서 안전하게 동작합니다.
마지막으로 위에서 살펴본 세 클래스에 대한 특징을 표로 간단히 정리하자면 아래와 같은 특성을 가집니다.
| - | String | StringBuffer | StringBuilder |
|---|---|---|---|
| Storage Area | String Constant Pool | Heap | Heap |
| Mutability | Immutable | Mutable | Mutable |
| Thread Safe | O | O | X |
| Performance | Fast | Very Slow | Fast |
오탈자 및 오류 내용을 댓글 또는 메일로 알려주시면, 검토 후 조치하겠습니다.