
CPU의 구조와 기능
명령어 파이프라이닝
CPU 성능은 컴퓨터 시스템의 프로그램 처리 시간에 직접 영향을 주기 때문에, 그 속도를 향상시키기 위하여 여러 가지 방벙들이 사용되고 있습니다. 그 중에서 가장 간단하면서도 분명한 효과를 얻을 수 있는 방법이 명령어 파이프라이닝(instruction pipelining) 입니다. 이것은 명령어를 실행하는데 사용되는 하드웨어를 여러 개의 독립적인 단계(stage)들로 분할하고, 그들로 하여금 동시에 서로 다른 명령어들을 처리하도록 함으로써 CPU의 성능을 높여주는 기술을 말합니다. 명령어 파이프라인은 분할되는 단계의 수가 많아질수록 처리 속도가 높아지는데, 최근에는 CPU의 속도를 더욱 높이기 위하여 여러 개의 명령어 파이프라인들을 설치하기도합니다.
2-단계 명령어 파이프라인
기본적으로 인출 사이클과 실행 사이클이라는 두 개의 단계로 이루어집니다. 그런데 이들 각 사이클의 동작을 처리하는 하드웨어를 독립적인 모듈로 구성할 수 있다면, 각 모듈이 서로 다른 명령어를 동시에 처리할 수 있다면 각 모듈이 서로 다른 명령어를 동시에 처리할 수 있습니다. 명령어를 실행하는 하드웨어를 인출 단계(fetch stage)와 실행 단계(execute stage) 라는 두 개의 파이프라인 단계들로 구성할 수 있습니다. 그 후 두 파이프라인 단계들에 하나의 클록 신호를 동시에 인가한다면, 그 단계들의 동작 시간을 일치시킬 수 있습니다. 즉 첫 번째 클록 주기 동안에 인출 단계가 첫 번째 명령어를 인출합니다. 그리고 두 번째 주기에서는 그 명령어가 실행 단계로 보내어져 처리되며 그와 동시에 인출 단계는 두 번째 명령어를 인출합니다. 이 주기 동안에 실행 단계에서 처리될 명령어는 첫 번째 클록 주기 동안에 미리 인출되었기 때문에, 두 번째 클록 주기가 시작되는 즉시 실행이 시작될 수 있습니다. 이와 같이 다음에 실행될 명령어를 미리 인출하는 것을 명령어 선인출(instruction prefetch) 혹은 인출 중복(fetch overlap) 이라고 합니다.
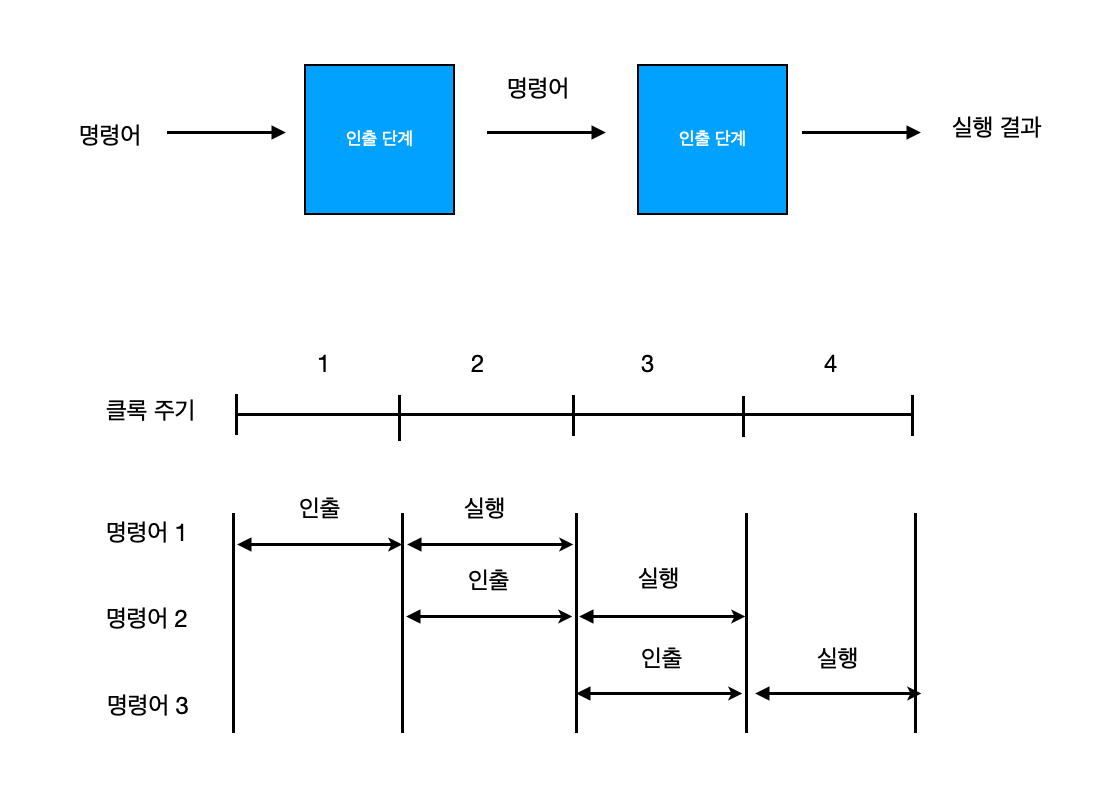
각 명렁의 실행에 걸리는 시간은 모두 두 주기씩이지만, 파이프라이닝의 특성에 의해 두 번째 명령어부터는 한 주기만에 실행이 완료되는 것과 같은 효과를 얻을 수 있습니다.
그러나 이와 같은 속도 향상은 명령어의 인출과 실행에 같은 길이의 시간이 소요되는 경우에만 얻을 수 있습니다. 실제 명령어 처리 과정을 분석해보면, 일반적으로 실행 단계에서 소요되는 시간이 인출 단계보다 더 깁니다. 2-단계 파이프라인을 이용하면 분명히 속도 향상을 얻을 수 있지만, 위와 같은 이유 때문에 실제로는 두 배만큼 빨라지지는 못합니다.
4-단계 명령어 파이프라인
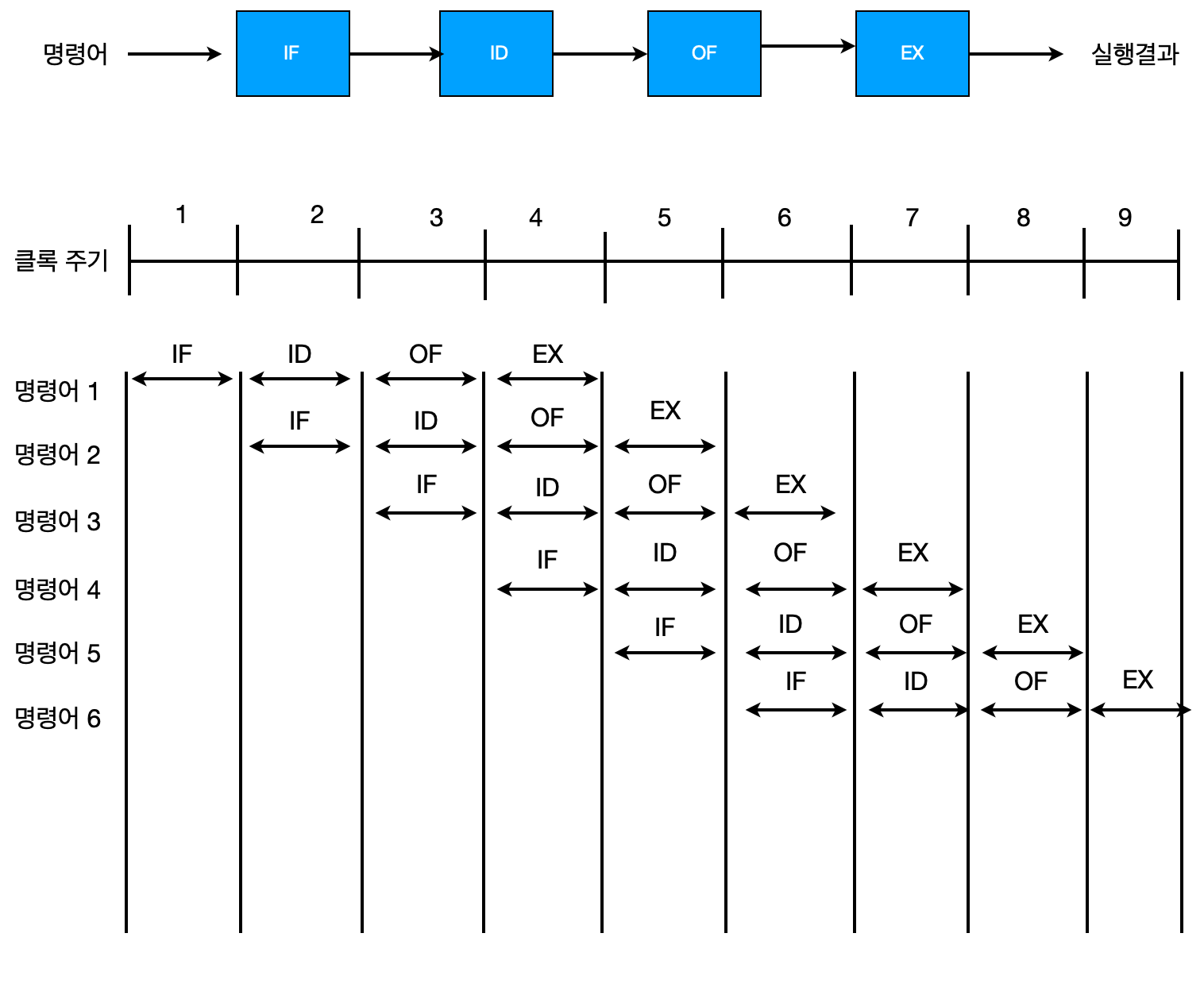
파이프라인 단계들의 처리 시간이 동일하지 않음으로 인하여 발생하는 효율 저하를 방지하는 방법은 처리 시간이 더 긴 파이프라인 단계를 여러 개로 분할함으로써, 단계들의 처리 시간이 거의 같아지도록 하는 것입니다. 예를 들어 다음과 같이 파이프라인을 네 단계로 구성하는 경우를 고려해보겠습니다.
- 명령어 인출(IF): 명령어를 기억장치로부터 인출합니다.
- 명령어 해독(ID): 해독기(decoder)를 이용하여 명령어를 해석합니다.
- 오퍼랜드 인출(OF): 기억장치로부터 오퍼랜드를 인출합니다.
- 실행(EX): 지정된 연산을 수행하고 결과를 저장한다.
이와 같이 4-단계 명령어 파이프라인으로 구성하면, 각 단계에서 걸리는 시간들이 거의 같아질 수 있습니다. 여기서 편의상 모든 단계들에서 같은 시간이 걸린다고 가정한다면, 명령어들이 연속적으로 실행되는 경우의 시간 흐름도는 아래와 같습니다.
파이프라이닝을 이용하여 얻을 수 있는 속도 향상을 일반적인 관계식으로 표현해보면, 먼저 파이프라인 단계의 수를 \(k\) , 실행할 명령어들의 수를 \(N\) 이라고 하면 파이프라이닝을 이용한 경우의 전체 명령어 실행 시간 \(T\) 는 식은 아래와 같습니다.
\[T = k + (N - 1)\]즉, 첫 번째 명령어를 실행하는데 \(k\) 주기가 걸리고, 나머지 \((N - 1)\) 개의 명령어들은 각각 한 주기씩만 소요됩니다. 만약 파이프라인이 되지 않았다면 \(N\) 개의 명령어들을 실행하는 데는 \(k \times N\) 주기가 걸리므로, 파이프라이닝을 이용함으로써 얻을 수 있는 속도 향상 \((SP)\) 식은 아래와 같습니다.
\[SP = \frac{k \times N}{k + (N - 1)}\]위 식을 통하여, \(k\) -단계 파이프라인을 이용하면 최대 \(k\) 배의 속도 향상을 얻을 수 있습니다.
그러나 이와 같은 파이프라인에 대하여 몇 가지 문제점들을 지적하면 다음과 같습니다.
- 어떤 명령어는 실행 과정에서 수행되지 않아도 되는 단계가 있지만 파이프라인 하드웨어를 단순화시키기 위해서는 모든 명령어들이 모든 단계를 통과하도록 해야합니다.
- 파이프라인 클록은 처리 시간이 가장 오래 걸리는 단계를 기준으로 정해져야합니다. EX 단계의 처리가 끝나기 전에는 그 결과를 보내주지 못하고 기다려야하기 때문입니다.
- IF 단계와 OF 단계는 모두 기억장치(혹은 캐시)를 엑세스해야 하는데, 하나의 기억장치 모듈을 두 단계가 동시에 엑세스할 수 없기 때문에 둘 중의 하나는 지연될 수 밖에 없습니다.
- 조건에 따라 다른 위치로 분기하도록 하는 조건 분기 명령어(conditional branch instruction)가 실행된다면, 미리 인출되어 파이프라인에서 처리되고 있던 명령어들이 무효화 될 수 있습니다. 결과적으로, 매 주기마다 한 개씩의 명령어 실행이 종료되던 것이 특정 클록 주기에서 비게 되어 사이클이 낭비되게 됩니다.
앞에서 지적된 문제점들은 파이프라이닝 구조가 가지고 있는 근본적인 것이기 때문에 완전히 해결할 수는 없지만, 그들을 보완하기 위한 많은 노력이 이루어지고 있습니다. 먼저, 두 번째 문제점을 보완하기 위한 방법으로서, 파이프라인 단계들을 더욱 작게 분할함으로써 처리 시간의 차이를 최소화 시켜주는 슈퍼파이프라이닝(superpipelining) 기술이 널리 사용되고 있습니다. 최근에는 대부분의 프로세서들이 10 단계 이상의 단계들로 분할된 명령어 파이프라인 구조를 사용하고 있습니다.
세 번째 문제점을 보완하기 위하여 파이프라인의 IF 단계와 OF 단계가 직접 액세스 하는 CPU 내부 캐시(internal cache)를 명령어 캐시와 데이터 캐시로 분리시키는 방법이 사용되고 있습니다.
슈퍼스칼라
슈퍼스칼라(superscalar)는 CPU의 처리 속도를 더욱 높이기 위하여 내부에 두개 혹은 그 이상의 명령어 파이프라인들을 포함시킨 구조를 말합니다. 매 클록 주기마다 각 명령어 파이프라인이 벼도의 명령어를 인출하여 동시에 실행할 수 있기 때문에, 이론적으로는 프로그램 처리 속도가 파이프라인의 수만큼 높아질 수 있습니다.
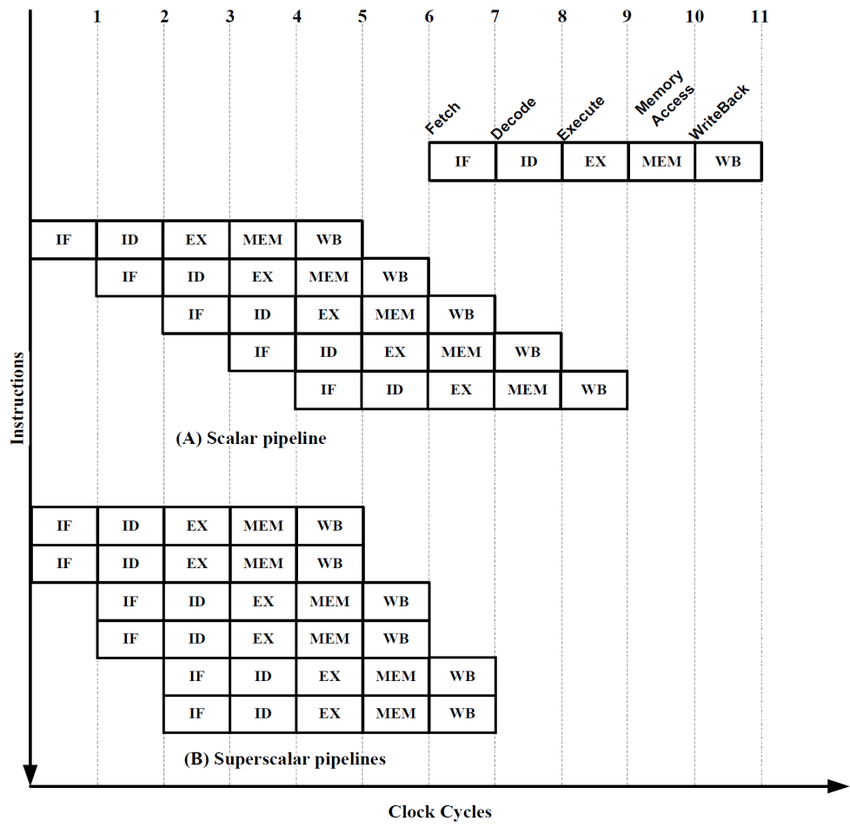
2-way 슈퍼스칼라 프로세서에서 유의할 점으로는 동시에 처리할 명령어들이 서로 간에 영향을 받지 않고 독립적으로 실행될 수 있어야한다는 것입니다. 즉, 두 명령어들 사이에 데이터 의존성(data dependency)이 존재하지 않아야 그들을 동시에 실행 할 수 있습니다.
명령어 세트
CPU의 기능은 명령어들에 의해 결정됩니다. 명령어들의 종류와 수는 CPU마다 약간씩 다른데, 어떤 한 CPU를 위해 정의되어 있는 명령어들의 집합을 **명령어 세트(instruction set)라 합니다. 명령어 세트를 설계하기 위해서는 다음과 같은 사항들을 먼저 결정해야 합니다.
- 연산 종류(operation repertoire): CPU가 수행할 연산들의 수와 종류 및 복잡도
- 데이터 유형(data type): 연산이 수행될 데이터들의 유형. 즉, 데이터의 길이(비트 수)와 수의 표현 방식(정수, 부동소수점 수) 등
- 명령어 형식(instuction format): 명령어의 길이, 오퍼랜드 필드들의 개수와 길이 등
- 주소지정 방식(addressing mode): 오퍼랜드의 주소를 지정하는 방식
연산의 종류
CPU가 수행할 수 있는 연산(혹은 동작)들의 종류는 컴퓨터에 따라 매우 다양합니다. 그러나 어떤 컴퓨터든 반드시 수행 할 수 있어야 하는 기본적인 연산들이 있는데, 그들을 분류하여 설명하면 다음과 같습니다.
- 데이터 전송: 레지스터와 레지스터 간, 레지스터와 기억장치 간, 혹은 기억장치와 기억장치 간에 데이터를 이동하는 동작입니다. 이 과정에서 기억장치의 주소를 계산해야하는 경우도 있습니다.
- 산술 연산: 사칙 연산과 같은 기본적인 산술 연산들을 말합니다. 이 연산들은 부호를 가진 정수들에 대해서는 물론이고, 부동소수점 수(floating-point number)에 대한 산술적 연산도 포함됩니다.
- 논리 연산: 데이터의 각 비트들 간에 대한 AND, OR, NOT 및 exclusive-OR 등과 같은 논리 연산을 수행해야합니다.
- 입출력(I/O): CPU와 외부 장치들 간의 데이터 이동을 위한 동작들이 수행됩니다. 이를 위해서는 특수한 I/O 명령어들과 주소지정 방식이 필요합니다.
프로그램 제어
명령어 실행 순서를 변경하는 연산도 필요합니다. 이 분류의 연산들로는 분기(branch) 와 서브루틴 호출(subroutine call) 등이 있습니다. 서브루틴 호출에 대해 처리하기 위해서는 다음과 같은 두 가지 기본적인 명령어들이 필요합니다.
- CALL 명령어: 서브루틴을 호출(call)하는 명령어
- RET 명령어: 서브루틴으로부터 원래 프로그램으로 복귀(return)시키는 명령어
CALL 및 RET 명령어들이 실행될 때는 스택을 반드시 사용해야 되기 때문에 그 과정을 살펴보기 위해 예를 들어 설명하겠습니다. 먼저 X번지에 위치한 서브루틴을 호출하는 CALL X 명령어의 실행 과정을 보면 CALL 명령어가 실행되어 서브루틴으로 분기될 때는 인터럽트의 경우와 마찬가지로 복귀할 주소(return address)를 스택에 저장해야합니다. 복귀 주소는 CALL 명령어의 다음에 위치한 명령어의 주소이므로, CALL 명령어가 실행되고 있는 현재 PC에 저장되어 있는 내용입니다. 그러므로 CALL X 명령어에 대한 마이크로-연산들은 다음과 같습니다.
| 주기 | 동작 |
|---|---|
| $t_{0}$ | MBR $\leftarrow$ PC |
| $t_{1}$ | MAR $\leftarrow$ SP, PC $\leftarrow$ X |
| $t_{2}$ | M[MAR] $\leftarrow$ $AC + MBR$, \(SP\) $\leftarrow$ \(SP - 1\) |
RET 명령어의 마이크로-연산은 다음과 같습니다.
| 주기 | 동작 |
|---|---|
| $t_{0}$ | SP $\leftarrow$ \(SP + 1\) |
| $t_{1}$ | MAR $\leftarrow$ SP |
| $t_{2}$ | PC $\leftarrow$ M[MAR] |
첫 번째 주기에서 SP의 내용을 1 증가시켜 복귀 주소가 저장된 스택 위치를 가리키게 한 다음에, 복귀 주소를 스택으로부터 인출하여 PC에 적재합니다.
명령어 형식
각 명령어는 CPU에 의해 실행될 때 제공해야 할 모든 정보를 퐇마하고 있어야 하는데, 그들 중에서 가장 기본적인 요소들을 나열하면 다음과 같습니다.
- 연산 코드(Operation Code): 수행될 연산을 지정해줍니다 (예: LOAD, ADD 등).
- 오퍼랜드(Operand): 연산을 수행하는 데 핋요한 데이터 혹은 데이터의 주소를 나타냅니다. 각 연산은 한 개 혹은 두 개의 입력 오퍼랜드들과 한 개의 결과 오퍼랜드를 가질 수 있습니다. 데이터는 CPU 레지스터 혹은 기억장치에 위치합니다.
- 다음 명령어 주소(Next Instruction Address): 현재의 명렁어 실행이 완료된 후에 다음 명령어를 인출할 위치를 나타냅니다. 순차적으로 다음 명령어가 실행되는 경우에는 이 부분이 필요하지 않으며 분기 혹은 호출 명령어와 같이 실행 순서를 변경하는 경우에만 필요합니다.
명령어를 구성하는 비티들은 용도에 따라 몇 개의 필드(field)들로 나눌 수 있는데, 필드의 수와 배치 방식 및 각 필드에 포함되는 비트 수를 정희한 것을 명령어 형식(instruction format)이라 합니다. 명령어의 길이, 즉 비트 수는 일반적으로 CPU가 한 번에 처리할 수 있는 데이터(단어)의 길이와 같습니다.
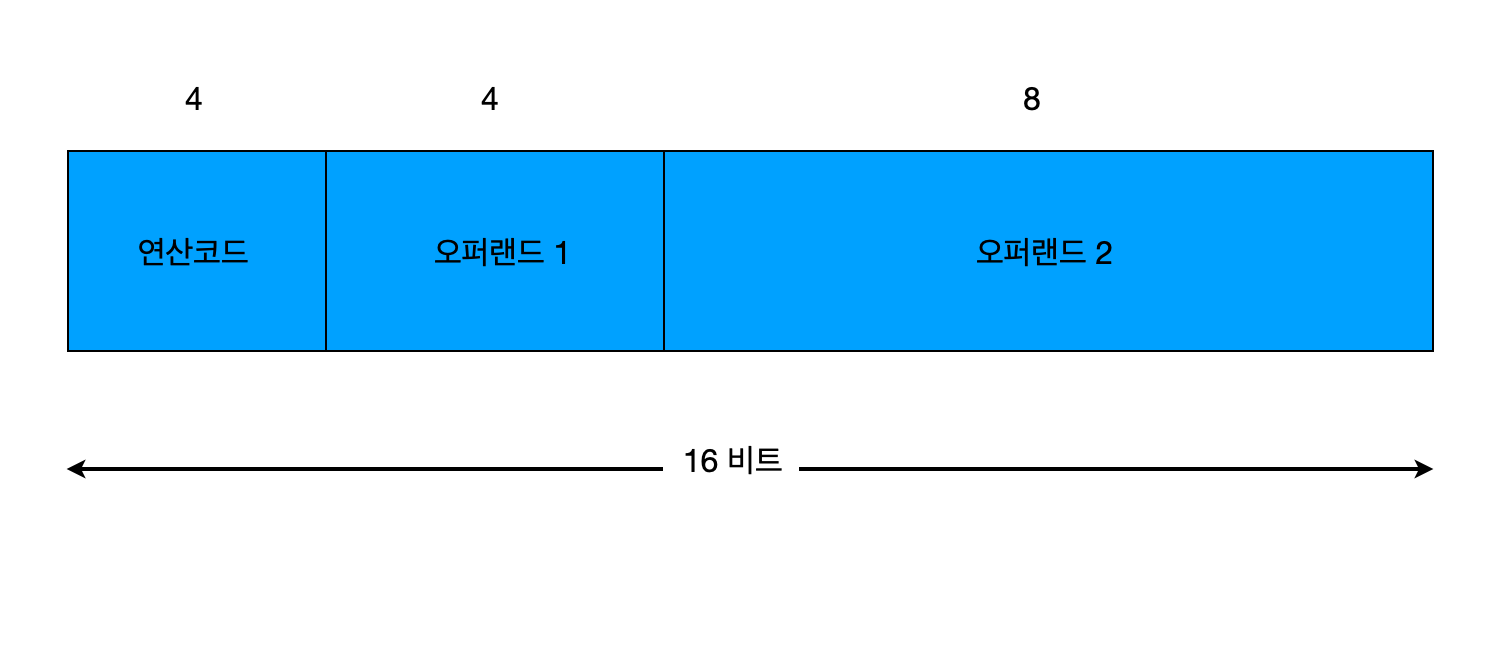
명령어의 길이가 고정된 상태에서 어느 한 필드의 비트 수를 증가시키면, 다른 필드의 비트 수는 그만큼 즐어들게 됩니다. 예를 들어 오퍼랜드를 한 개만 필요로 하는 명령어의 경우에는 두 개의 오퍼랜드 필드들을 합하여 12비트를 사용할 수 있습니다. 이 경우 만약 오퍼랜드가 2의 보수로 표현되는 데이터라면, 그 표현 범위는 (-2048~ +2047)이 되고, 기억장치 주소라면 최대 \(2^12 = 4096\) 개의 기억장치 주소를 지정할 수 있습니다. 오퍼랜드 필드는 오퍼랜드가 아래와 같은 세가지 중의 어떤 것인지에 따라 필요한 비트 수가 달리질 수 있으며, 배정되는 비트들의 수에 따라 각각의 범위가 결정됩니다.
- 데이터: 표현 가능한 수의 크기가 결정됩니다.
- 기억장치 주소: CPU가 오퍼랜드 인출을 위하여 직접 주소를 지정할 수 있는 기억장치 영역의 범위가 결정됩니다.
- 레지스터 번호: 데이터 저장에 사용될 수 있는 내부 레지스터들의 수가 결정된다.
해당 글은 컴퓨터구조론(김종현 저)을 읽고 공부한 내용을 정리한 글입니다.
오탈자 및 오류 내용을 댓글 또는 메일로 알려주시면, 검토 후 조치하겠습니다.