
들어가기에 앞서
서버에서 보안, 인증, 권한 부여 등을 확인하고 관리하는 방식은 대표적으로 쿠키, 세션, 토큰 3가지가 있습니다.
이 글에서는 3가지 방식(토큰은 JWT 기반)에 대해서 알아보고자 합니다.
추가로 Spring Framework 환경에서는 어떤 방식으로 세션을 처리하는지 간단한 예제와 설명도 함께 작성하도록 하겠습니다.
JWT(JSON Web Token)
역사
JWT는 JSON Web Token의 줄임말로 일반적으로 웹 애플리케이션에서 인증 및 권한 부여 목적으로 사용되는 표준입니다.
XML을 이용하여 인터넷을 통해 데이터를 전송하던 2000년대 초, 웹 애플리케이션이 점점 가볍고 이동성이 높은 JSON 데이터 전송 방식을 선호하게 되는 시점과 함께 JWT는 JSON 형식으로 데이터를 안전하게 전송하기 위한 수단으로 개발 되었습니다.
배경
웹 애플리케이션이 더욱 복잡해지고 여러 사용자가 이용함에 따라 안전하고 명백한 방식으로 웹 애플리케이션을 처리할 필요성이 대두 되었습니다.
또한 이전에는 서버가 세션 기반 인증으로 사용하는 것이 일반적이었지만, 이 방법은 확장성, 상태 관리에 어려움을 겪는 문제가 있었습니다.
JWT는 상태 비저장, 확장성 및 다양한 플랫폼에서 사용할 수 있는 장점을 필두로 클라이언트에게 토큰을 발급합니다.
토큰을 발급 받은 클라이언트는 토큰 자체에 포함된 권한 정보나 서비스를 사용하기 위한 정보(Self-contained)를 이용하기 때문에 따로 서버에 데이터를 저장할 필요 없이 서버에 대한 향후 요청을 할 수 있게 되었습니다.
특징
JWT는 Header, Payload, Signature 이렇게 3개의 부분으로 구성되어 있습니다.
각 부분에 대해서 간략하게 설명하자면
Header: 토큰의 유형과 토큰 서명에 사용되는 알고리즘에 대한 정보를 포함합니다.
Payload: 토큰이 나타내는 실제 데이터를 포함하는 부분입니다.
ID 또는 Role과 같이 사용자 정보를 서버에 저장하는 방식이 아닌, 토큰 자체가 정보를 가지고 있는 방식입니다.
Signature: 토큰이 변경됐는지 확인하는데 사용하는 부분입니다.
Signature는 서버에 저장한 키를 사용하여 생성합니다.
Byte를 적게 차지하는 것이 유리하기 때문에 독특하게도 JWT는 JSON 형식으로 데이터를 저장할 때 key 값을 3글자로 줄이는 관행이 있습니다.
- sub: 인증 주체(subject)
- iss: 토큰 발급처
- typ: 토큰의 유형(type)
- alg: 서명 알고리즘(algorithm)
- iat: 발급 시각(issued at)
- exp: 말료 시작(expiration time)
- aud: 클라이언트(audience)

실제 데이터들은 claim(메세지)이라고 불리며, JWT는 JSON을 이용해서 claim을 정의합니다.
JWT는 위 사진 우측의 Header, Payload, Signature 3개의 부분과 같이 JSON 형태로 표현한 것인데, JSON은 개행 문자가 있기 때문에, REST API 호출 시 HTTP Header에 넣기가 불편합니다.
그래서 JWT는 claim JSON 문자열을 base64 인코딩을 통해 하나의 문자열로 변환합니다.
아래는 JWT가 Authentication을 처리하는 흐름입니다.
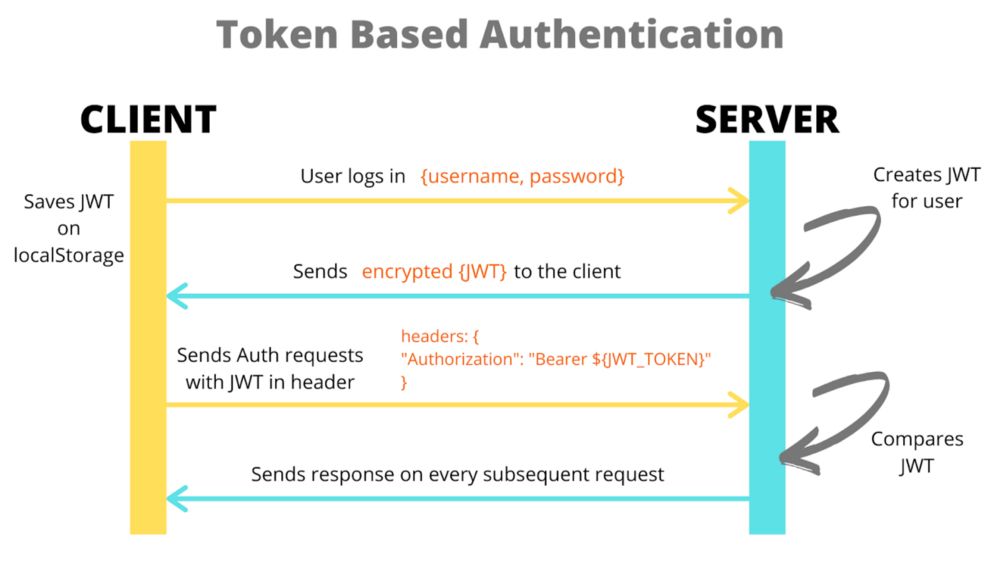
위 그림에서 눈 여겨 볼 점은 OAuth와 같은 단순 암호화된 문자열을 들고 있는 방식과 달리, 클라이언트에게 전달 받은 토큰의 내용을 서버 사이드에서 저장 & 관리할 필요 없이 Self-contained한 내용( 아이디, 인가 정보 등)을 확인하고 이에 따라 응답만하게 됩니다.
장점
- 보안(Security): JWT는 토큰의 변조를 탐지할 수 있는 서명으로 안전하도록 설계되었습니다.
서명은 서버에만 알려진 키를 사용하여 생성되므로 서버만이 토큰을 발급하고 확인할 수 있습니다. - 무상태(Stateless): JWT를 사용하게 되면 서버가 세션 데이터를 저장할 필요가 없으므로 여러 서버에 걸쳐 확장 가능하고 쉽게 관리할 수 있습니다.
- 상호 운용성(Interoperability): JWT는 JSON을 기반으로 사용하기 때문에 다양한 플랫폼 및 언어에서 작업이 용이합니다.
- 사용자 정의(Customizable): JWT의 payload는 모든 데이터를 포함할 수 있으므로 다양한 사용 사례에 맞게 사용자 정의에 용이합니다.
그 중 2번째 장점(stateless)에 대해서 어떤 이점이 있는지, 부가 설명을 해보고자 합니다.
REST API Server를 Stateless하게 설계하게 되면 얻게 되는 몇 가지 장점이 있습니다.
어떤 이유로 Stateless로 서버를 설계하는지, JWT는 어떤 점이 부합하는지 알아 보도록 하겠습니다.
REST API 서버를 Stateless로 설계해야 하는 이유
- Scalability(확장성): Stateless 서버는 각 요청에 요청을 처리하는 데 필요한 모든 정보가 들어 있으므로 요청은 서버 간에 세션 상태를 동기화할 필요 없이 여러 서버에 분산될 수 있습니다.
- Reliability(신뢰성): 상태 비저장 서버는 세션 상태를 유지하는 서버보다 안정적입니다. 관리할 세션 상태가 없기 때문에 버그나 오류가 발생할 가능성이 적습니다.
- Simplicity(단순성): 상태 비저장 서버는 세션 상태를 유지하는 서버보다 설계 및 구현이 간단합니다. 세션 상태에 의존하지 않음으로써 서버 로직을 단순화하여 보다 간단하고 유지관리 가능한 코드베이스로 이어질 수 있습니다.
- Caching(캐싱): 상태 비저장 서버는 각 요청에 요청을 처리하는 데 필요한 모든 정보가 포함되어 있기 때문에 프록시 또는 CDN과 같은 중개자가 쉽게 캐시할 수 있습니다. 이렇게 하면 성능이 향상되고 서버 부하가 감소할 수 있습니다.
요약하면 REST API 서버를 상태 비저장으로 설계하면 향상된 확장성, 안정성, 단순성 및 캐싱을 포함한 몇 가지 이점을 제공합니다. 각 요청을 독립적으로 처리함으로써 서버는 요청을 보다 효율적으로 처리하도록 설계되어 응답성과 신뢰성이 높은 웹 서비스로 이어질 수 있습니다.
단점
- Cookie, Session과는 다르게 base64 인코딩을 통한 정보를 전달하므로 전송 데이터 양으로 인한 부하가 생길 수 있습니다.
- payload는 암호화가 되어있지 않기 때문에 민감한 정보를 저장할 수 없습니다.
- 토큰이 탈취 당한다면 토큰이 만료될 때까지 대처가 불가능합니다.
세션(Session)
배경
REST API Server에서 세션(Session)은 일반적으로 서버와 클라이언트 간의 Stateful 통신을 나타냅니다.
REST API는 Sateless로 설계 되었으며, 이는 클라이언트의 각 요청이 이전 요청에 의존하지 않고 요청을 수행하는데 필요한 모든 정보를 포함해야 한다는 것을 의미합니다.
그러나 일부 응용 프로그램은 서버가 여러 요청에 걸쳐 클라이언트에 대한 일부 정보를 유지하도록 요구하게 되는데, 여기서 세션이 등장하게 되는 배경의 시작입니다.
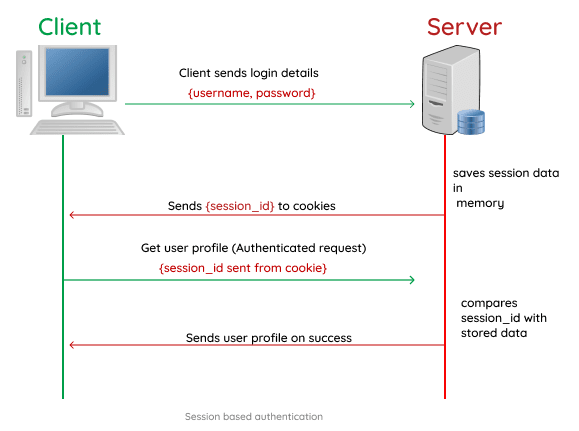
클라이언트가 REST API 서버와의 세션을 시작하면 서버는 세션 ID로 알려진 고유 식별자를 생성하여 클라이언트로 다시 보냅니다.
그런 다음 클라이언트는 각 후속 요청에 이 세션 ID를 포함하여 서버가 클라이언트를 식별하고 필요한 상태 정보를 유지할 수 있습니다.
서버는 이 상태 정보를 메모리, 데이터베이스 또는 기타 저장 메커니즘에 저장하고 이를 사용하여 클라이언트의 요청에 대한 응답을 사용자 정의할 수 있습니다.
세션은 클라이언트 또는 서버에 의해 종료되거나 일정 기간 동안 사용하지 않으면 만료될 수 있습니다.
특징
- 상태 저장 통신(Stateful communication): 세션을 사용하면 클라이언트와 서버 간의 상태 저장 통신이 가능하므로 서버는 사용자 ID 및 권한 부여 상태와 같은 클라이언트별 정보를 추적할 수 있습니다.
- Session ID(세션 아이디): 클라이언트가 세션을 시작하면 서버는 세션 아이디로 알려진 고유 식별자를 생성하여 쿠키에 저장 후 클라이언트로 다시 보냅니다. 그런 다음 클라이언트는 서버에 대한 각 후속 요청에 이 세션 아이디를 통해서 클라이언트를 식별합니다.
- Server-side storage(서버 사이드 저장소): 서버는 일반적으로 서버 측에서 세션 데이터를 메모리 또는 데이터베이스와 같은 저장 메커니즘에 저장합니다. 이렇게 하면 서버가 필요에 따라 세션 데이터를 검색하고 보안을 유지할 수 있습니다.
- Expiration and termination(만료 및 종료): 세션이 일정 시간 후에 만료되도록 설정하거나 서버 또는 클라이언트에서 수동으로 종료할 수 있습니다. 이를 통해 보안 위험을 줄이고 세션 데이터가 필요 이상으로 오래 보관되지 않도록 할 수 있습니다.
- Session hijacking prevention(세션 가로채기 방지): 세션은 HTTPS와 같은 보안 전송 프로토콜을 사용하고 추측하거나 예측하기 어려운 세션 ID를 생성하여 하이재킹으로부터 보호할 수 있습니다.
- Scalability(확장성): 세션은 특히 대규모 분산 시스템에서 확장성 문제를 야기할 수 있습니다. 이러한 문제를 해결하기 위해 일부 REST API Server는 분산 캐싱 및 로드 밸런싱 기술을 사용하여 세션 데이터를 여러 서버에 분산시킵니다.
- Impact on performance(성능에 미치는 영향): 세션은 서버 측 저장 및 검색이 필요하므로 REST API 서버의 성능에 영향을 미칠 수 있습니다. 이러한 영향을 최소화하기 위해 일부 REST API 서버는 캐슁 메커니즘을 사용하여 자주 액세스하는 세션 데이터를 메모리에 저장합니다.
전반적으로 세션은 REST API 컨텍스트에서 클라이언트와 서버 간의 상태 저장 통신을 유지하는 데 유용한 메커니즘을 제공할 수 있습니다.
그러나 일부 복잡성과 성능 오버헤드가 발생할 수 있으므로 신중하게 사용해야 합니다.
REST API 서버를 설계할 때 세션 기반 접근 방식과 상태 비저장 접근 방식 간의 절충을 신중하게 고려하는 것이 중요합니다.
Spring Framework에서의 Session
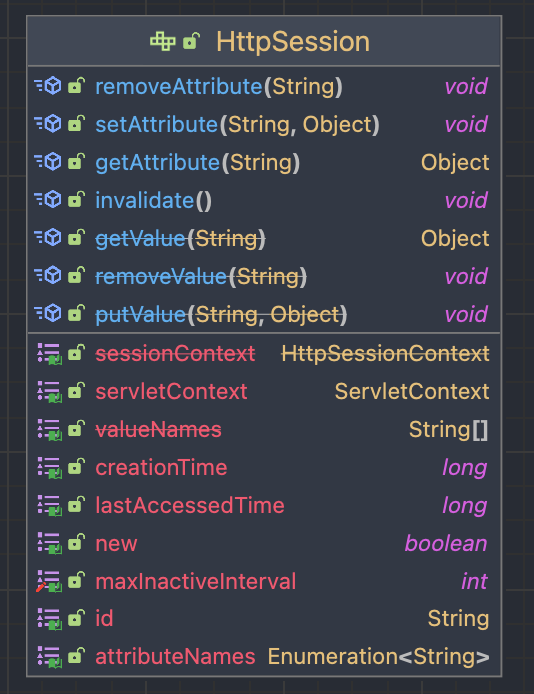
Spring Framework는 HttpSession 인터페이스를 활용하여 사용자의 세션과 관련된 데이터를 저장하고 처리합니다.
HttpSession은 퍼사드 패턴(Facade Pattern)을 사용하여 관리하고 있습니다. 퍼사드 패턴에서 사용 될 통합 인터페이스로는 StandardSessionFacade를 구현하였고 HttpSession 기본 구현체로는 StandardSession객체를 구현했습니다.
퍼사드 패턴(Facade Pattern)이란?
먼저 퍼사드(Facade)는 프랑스어 Façade 에서 유래된 단어로 건물의 ‘외관’이라는 뜻입니다.
서브 시스템(내부 구조)에 있는 인터페이스들에 대한 통합된 인터페이스(외벽)를 제공하는 패턴입니다.
이로써 내부 시스템의 복잡도를 감추기 위해 복잡한 기능을 감싸고 상호 작용할 더 단순한 메소드를 제공하는 계층을 생성하고 서브시스템과 상호 작용 복잡도를 낮추는데 의미가 있습니다.
생성
최초에 HttpSession 을 사용하기 위해서는 HttpSession.getSession() 메소드를 통해서 객체를 생성하여 사용하게 되는데, 기본 구현체인 StandardSession를 주입받는 StandardSessionFacade를 통해 서버내의 세션을 관리하게 됩니다.
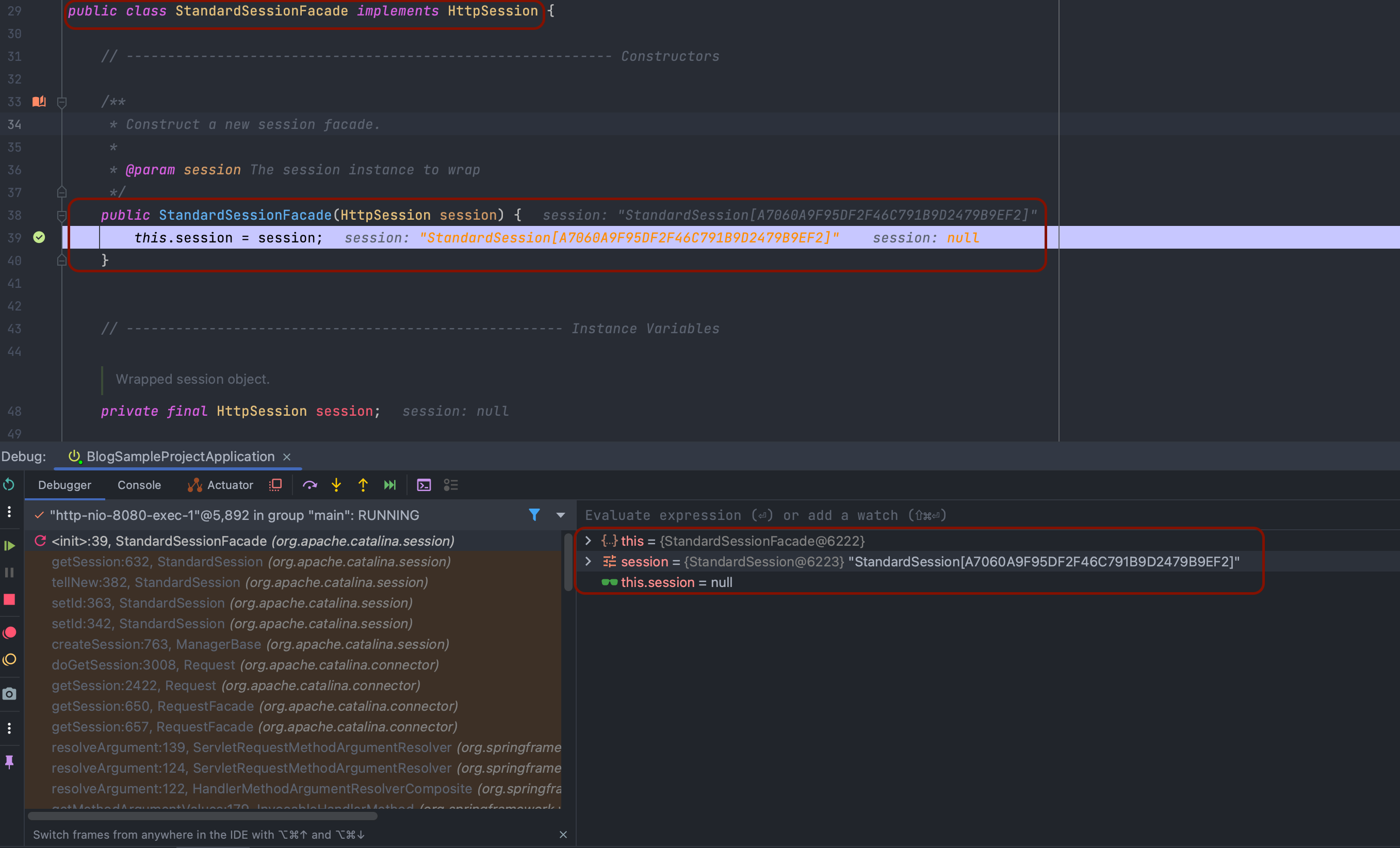
사실 HttpSession.getSession() 을 통해 HttpSession을 생성하기 이전에 많은 일들이 발생합니다.
간단하게 작성해 보면 먼저 org.apache.catalina.connector.Request.doGetSession(), org.apache.catalina.Manager.createSession(sessionId) 메소드를 통해서 실제로 세션 생성 및 validation이 이루어 집니다.
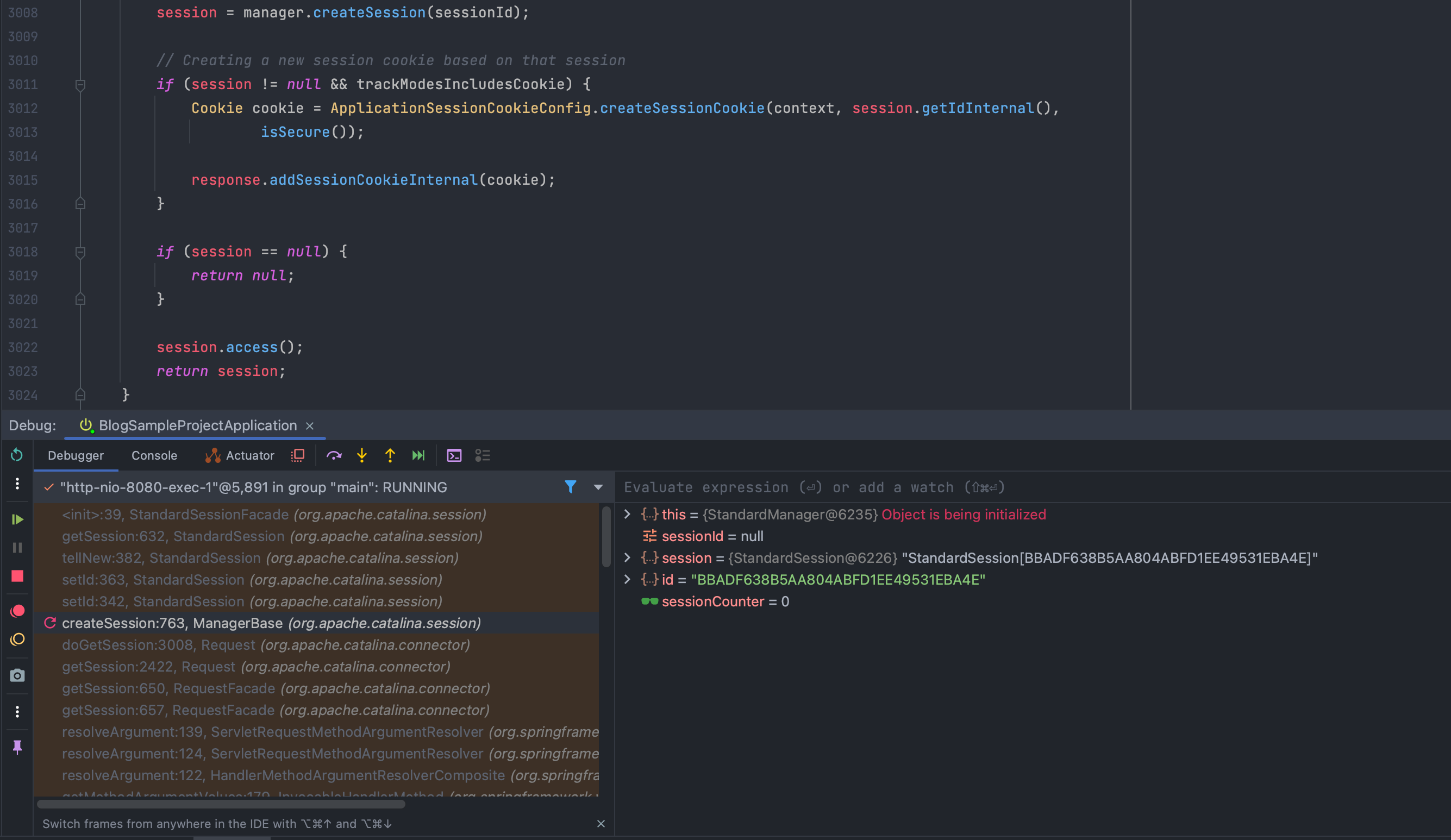
org.apache.catalina.connector.Request.doGetSession()
세션을 생성하고, 생성한 세션 아이디를 value에 담아 JSESSIONID라는 이름의 name으로 Response 쿠키에 추가합니다.
추가로 세션 아이디는 org.apache.catalina.util.StandardSessionIdGenerator.generateSessionId() 메소드를 활용하여 생성합니다.
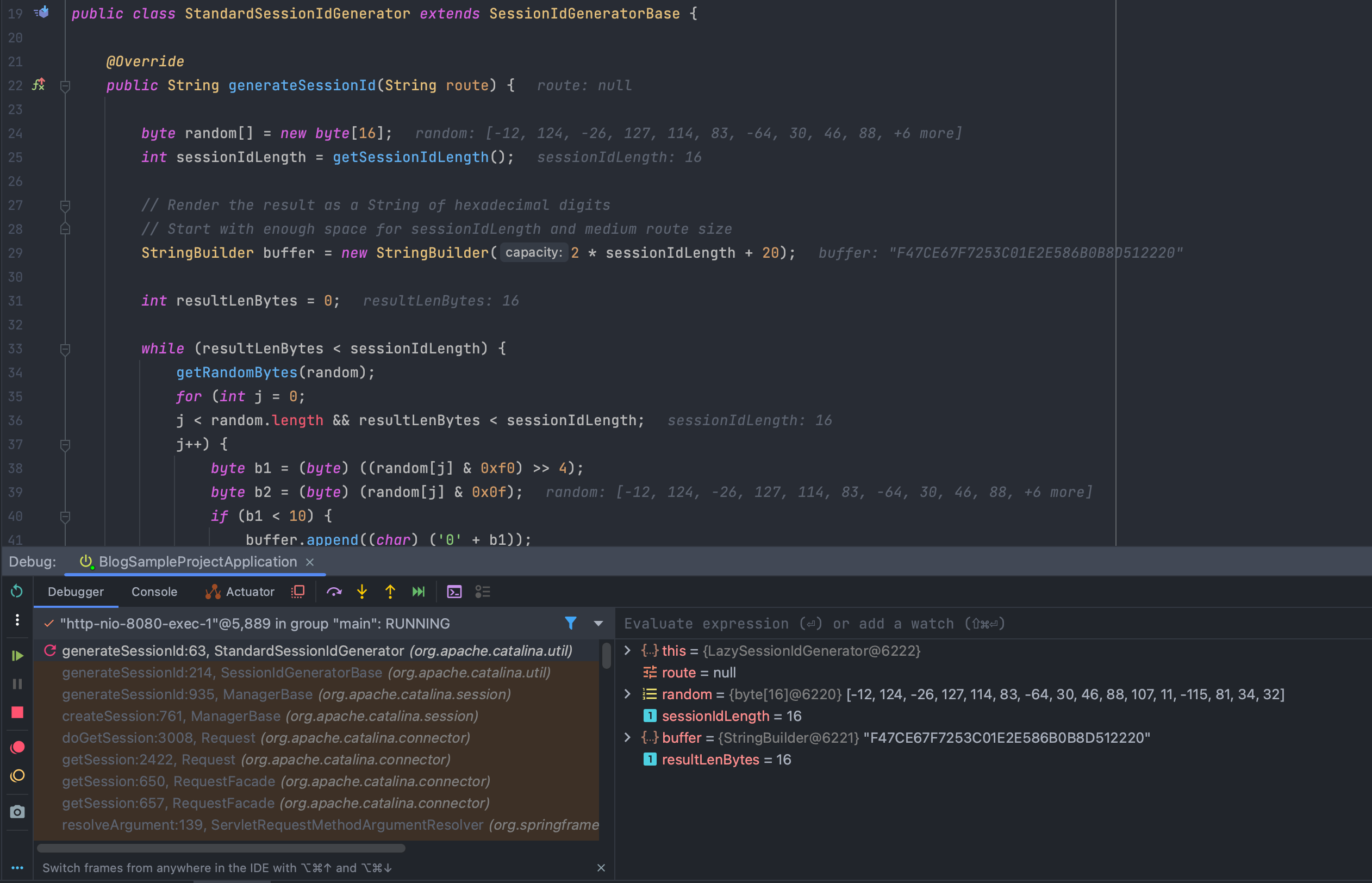
16바이트 길이의 랜덤값을 뽑아서 16진수 32자 문자열을 만듭니다.
또generateSessionId()내부에서route를 인자로 받는generateSessionId(String)메소드를 사용하는데, 해당 인자는 서블릿 컨테이너에 접속한 사용자를 구분하는 값으로 Route나 jvmRoute로 사용됩니다.
Route로 받는 값이 있는 경우 문자열 뒤에 “.route”를 추가하고, 그렇지 않을 경우는 “.jvmRoute”를 추가하게 됩니다.
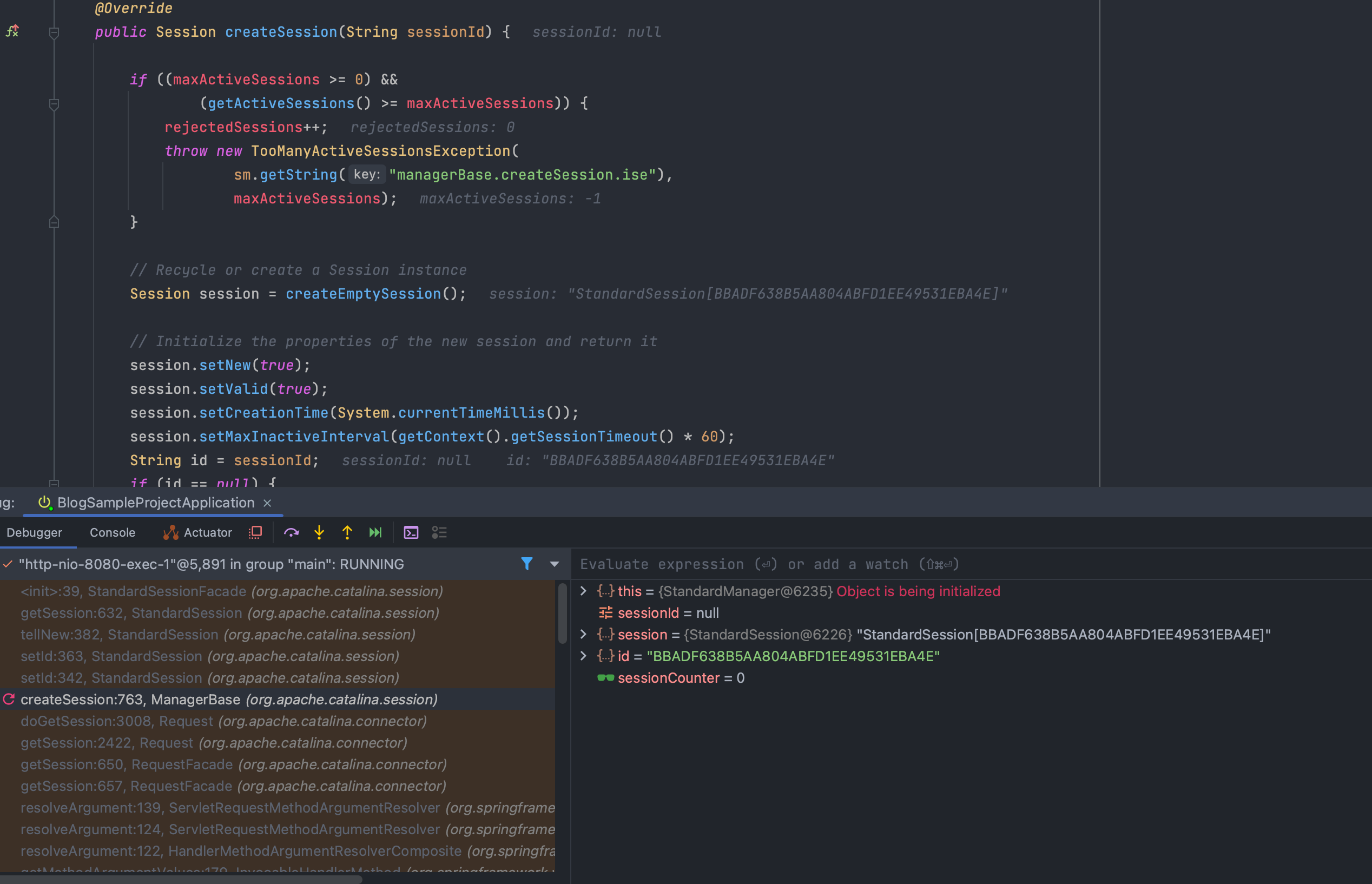
org.apache.catalina.session.ManagerBase.createSession(sessionId)
MaxActiveSession 갯수를 validation 하고, 최초 세션 생성 시(createEmptySession) 세션의 정보(세션 생성 시간, 세션 아이디, 세션 유효 시간 등…)을 설정합니다.
간략하게나마 HttpSession 객체가 어떻게 생성되는지 확인 했습니다.
다음은 HttpSession이 제공하는 대표적인 method setAttribute(), getAttribute(), invalidate() 를 통해서, HttpSession 객체는 어떤 식으로 세션을 관리하는지 알아보겠습니다.
주요 메소드
void setAttribute(String, Object)
첫번째 파라미터로 넘어온 이름으로 두번째 객체를 세션에 바인딩합니다.
이미 같은 이름의 객체가 세션에 바인딩 되어 있다면 후에 들어온 객체로 덮어쓰여집니다.
또 전달된 값이 null이라면 removeAttribute()를 호출하는 것과 같습니다.
여기서 세션에 바인딩한다는 의미는 생성된 HttpSession 객체 내부에 선언 되어 있는 attributes 맴버 변수에 저장한다는 의미 입니다.
파라미터로 넘어온 key, value 값들을 각각 validation 후 ConcurrentHashMap로 선언 된 attributes 객체에 put 합니다.
먼저 각 key, value 값이 null인지 체크합니다.(value가 null일시 removeAtttibute()를 호출합니다.)
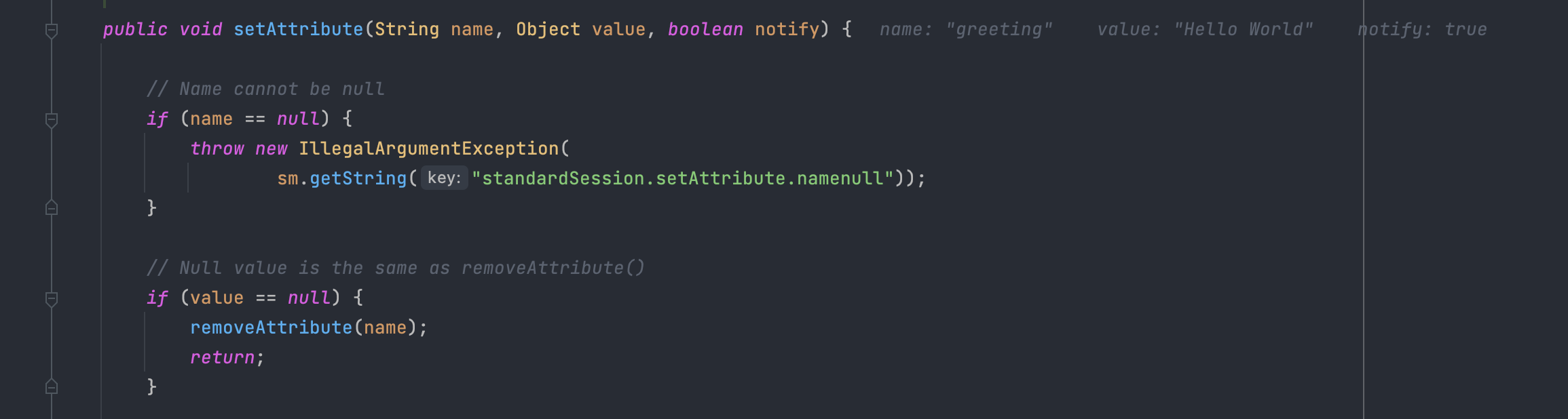
그 후 Session이 expired 되었는지, Session이 클러스터 환경의 여러 JVM에 분산 될 수 있는지 여부를 확인합니다.

앞의 과정을 걸친 후 최종적으로 attributes 객체에 등록됩니다.

ConcurrentHashMap 이란?
Map Interface를 Thread-Safe한 방식으로 구현한 것으로 여러 스레드에서 동시에 접근하고 수정하는 Multi-Thread 환경에서 사용하는 것이 적합한 구현체입니다.
Object getAttribute(String)
지정한 이름으로 바인딩된 객체를 반환하거나, 해당 이름으로 바인딩된 객체가 없으면 null을 반환합니다.
setAttribute()를 통해 attributes에 저장된 객체를 key 이름으로 가져옵니다.
attributes.get(key) 이전에 Session이 expired 되었는지 validation을 합니다.
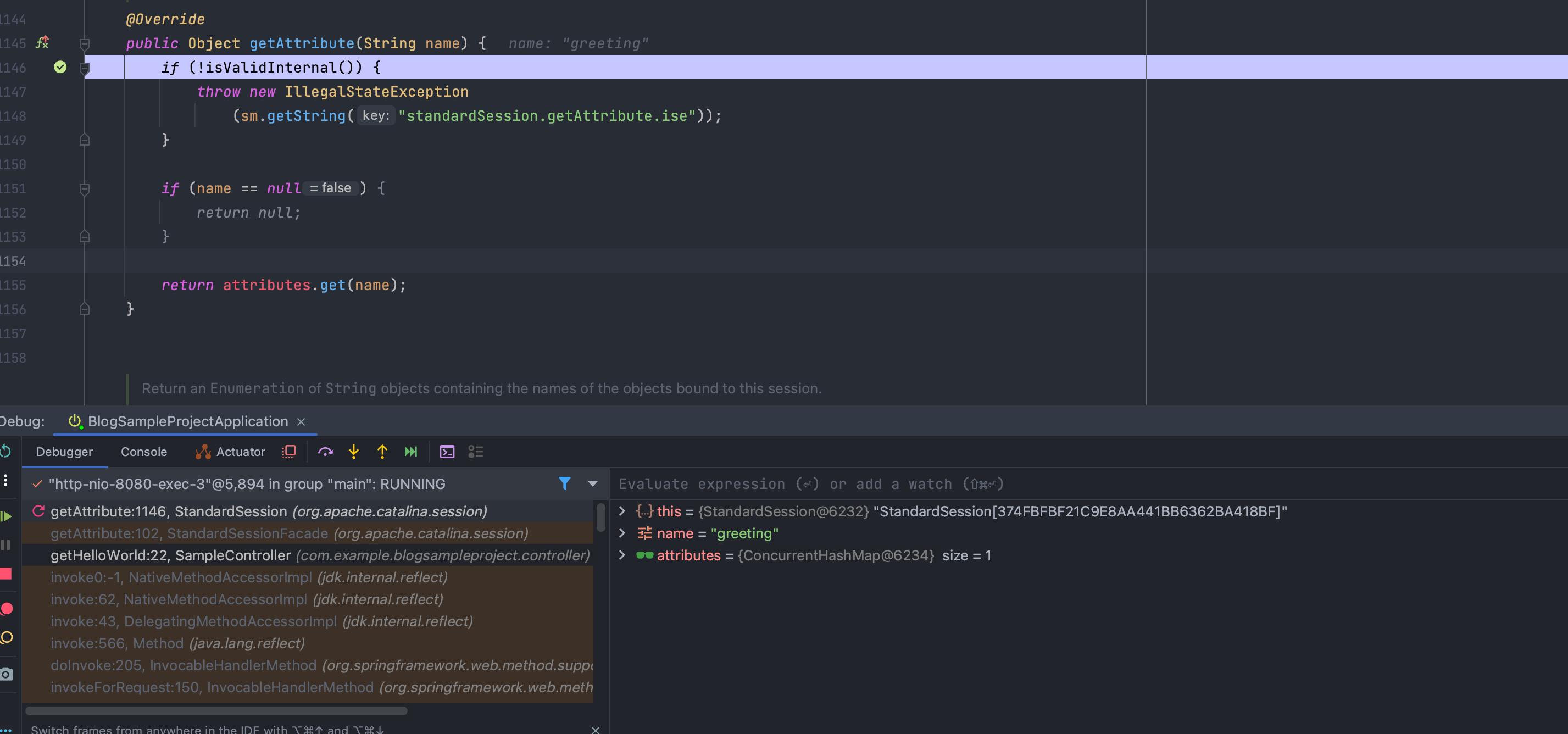
서버는 어떻게 클라이언트별 세션 아이디와 서버의 세션 아이디를 확인하는지에 대해
세션 객체가 생성되면 서버는 리스폰즈에 쿠키에 세션 아이디(JSESSIONID) 값을 반환합니다.
그 후 클라이언트는 해당 세션 아이디 기반으로 서버에 여러 요청을 하게 됩니다.
그렇다면 서버는 어떻게 클라이언트를 식별하고 요청을 처리하는지 알아 보도록 하겠습니다.
예를 들어 다음과 같은 코드가 있다고 가정했을때, 해당 URL을 호출해봅니다.
1
2
3
4
5
6
7
8
9
10
@RestController
@RequestMapping("/sample")
public class SampleController {
@GetMapping("greeting")
public Object getGreeting(HttpSession httpSession) {
return httpSession.getAttribute("greeting");
}
}
최초에 클라이언트가 서버에 요청하게 되면 먼저 org.apache.catalina.connector.CoyoteAdapter 는 postParseRequest(rg.apache.coyote.Request, Request, org.apache.coyote.Response, Response) 메소드를 통해 HTTP 헤더 구문을 분석합니다.
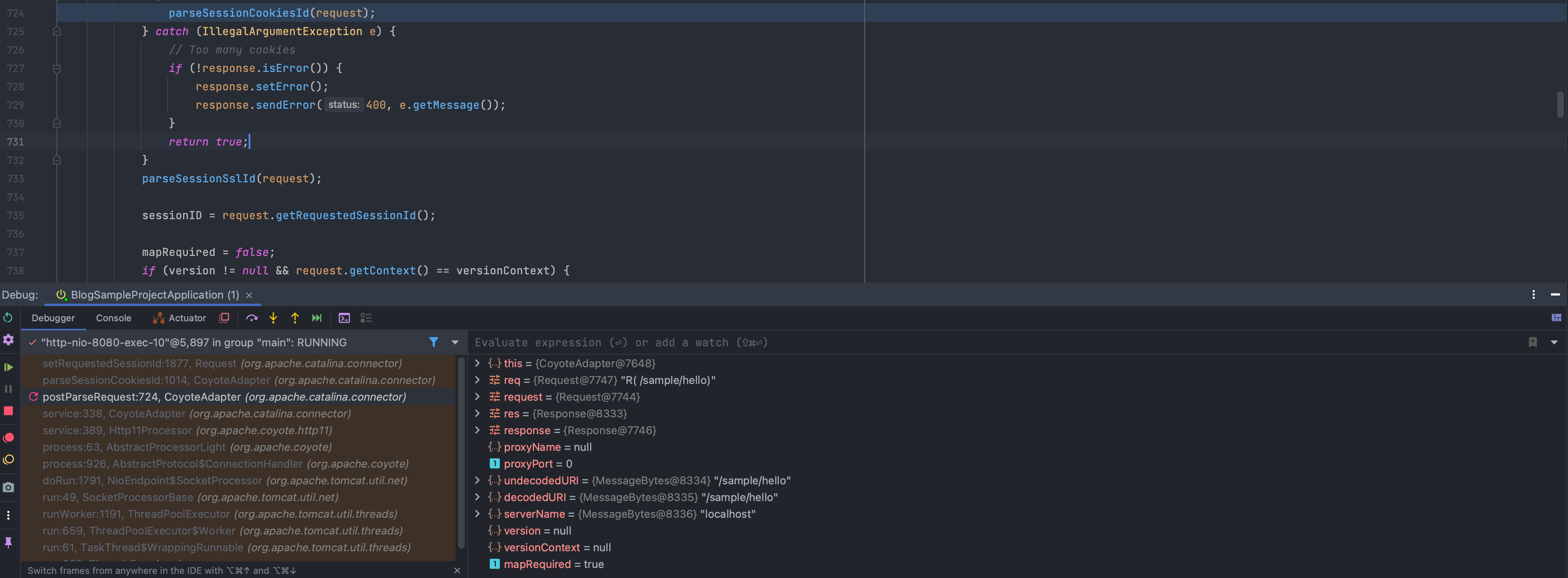
그 중 내부 메소드 중 parseSessionCookiesId(org.apache.catalina.connector.Request)는 쿠키에 있는 세션 아이디를 찾아 org.apache.catalina.connector.Request 요청 세션 아이디로 저장합니다.
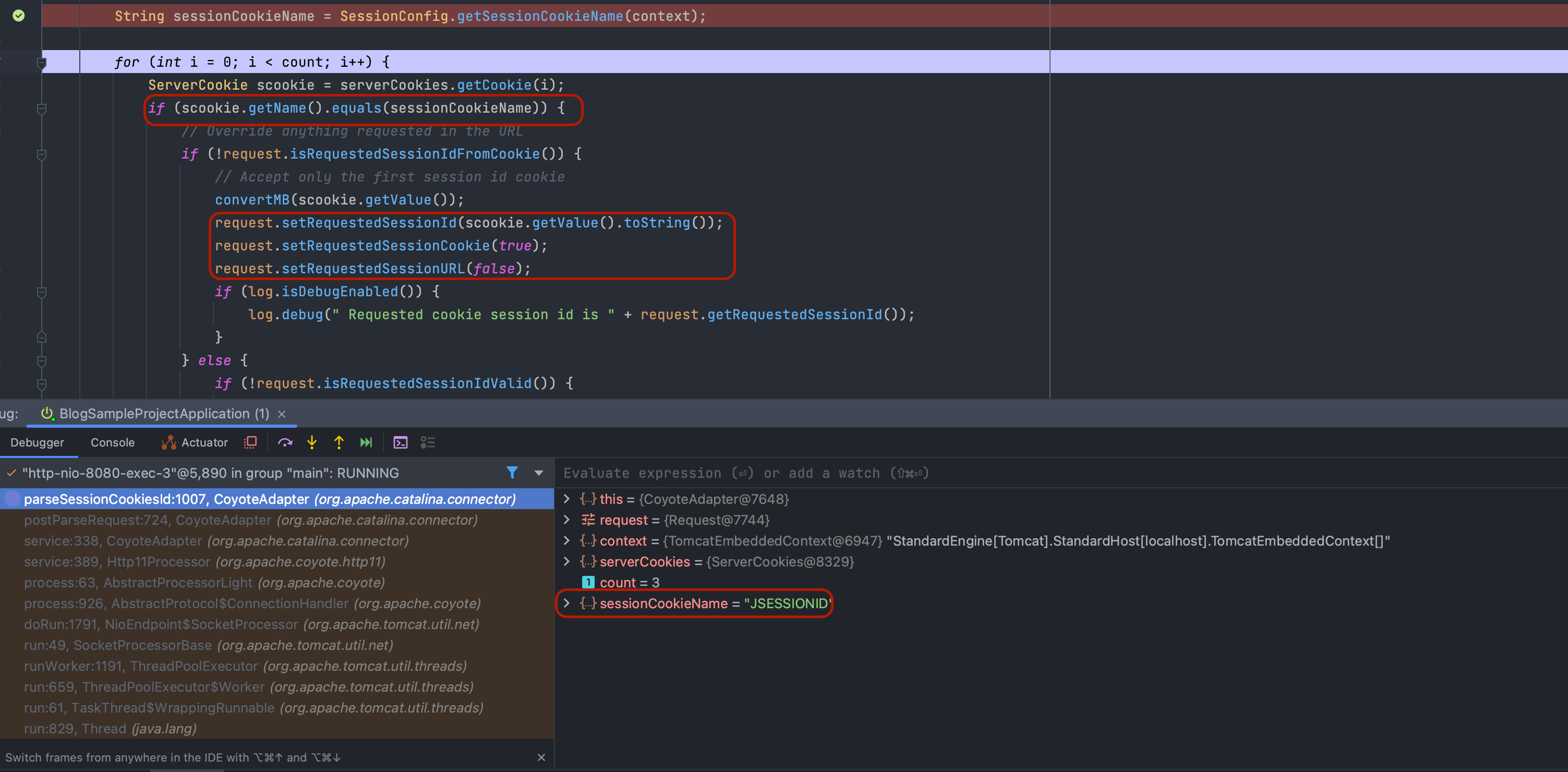
parseSessionCookiesId(org.apache.catalina.connector.Request)를 통해 요청 세션 아이디를 저장합니다.
내부에 저장된 세션 아이디를 사용하여 org.apache.catalina.connector.Request는 org.apache.catalina.Manager에게 해당 세션 아이디를 가지는 객체가 있는지 찾는 요청을 보냅니다.
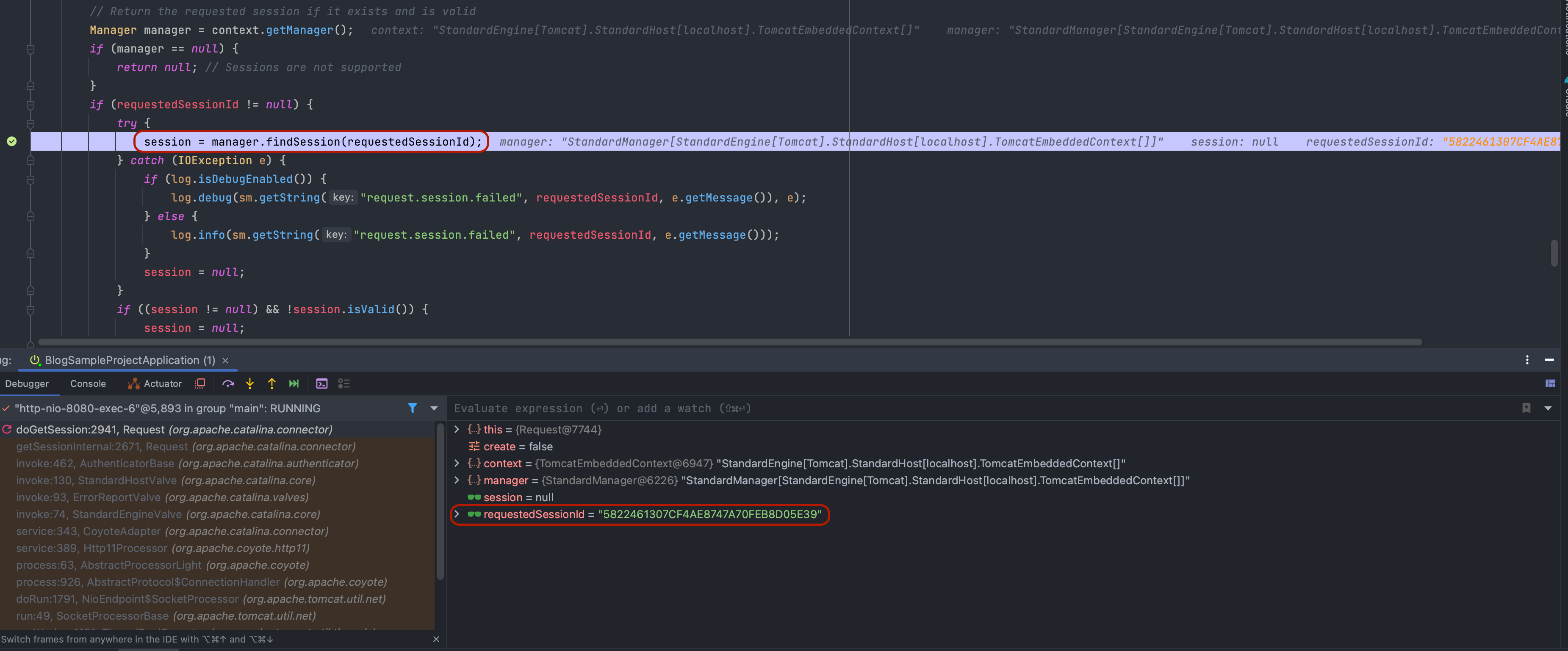
요청하게 되면 org.apache.catalina.Manager의 기본 구현체인 org.apache.catalina.session.ManagerBase.findSession(String)이 동작하게 됩니다.
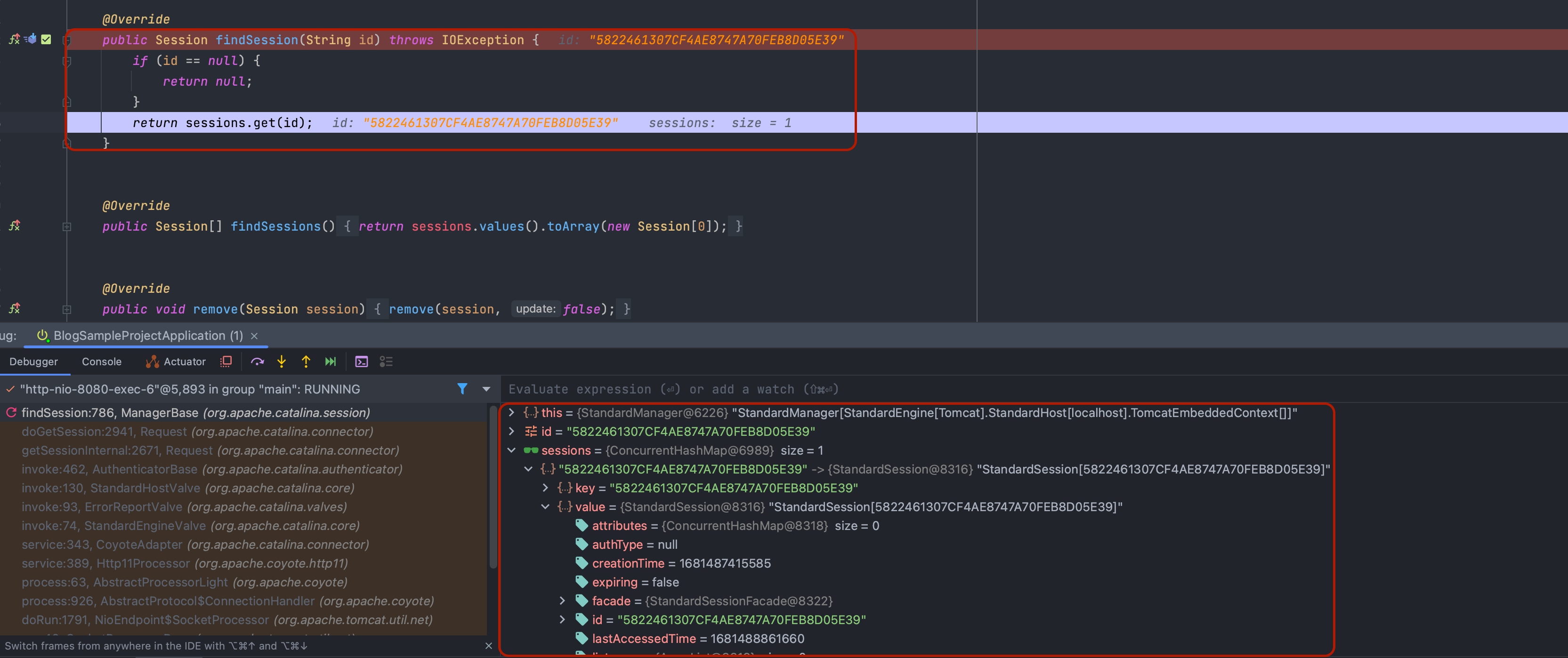
결과적으로 세션 아이디가 일치한 세션 객체를 찾아 클라이언트를 식별하게 됩니다.
세션 아이디가 서버의
ConcurrentHashMap.sessions에 존재하지 않는다면, 서버는 새로운 세션 객체를 생성해서 반환하게 됩니다. 하지만 해당 세션의 attributes에 값은 존재하지 않습니다.
그 후 클라이언트의 세션 아이디로 식별된 세션 객체는 org.apache.catalina.authenticator.AuthenticatorBase에서 클라이언트의 인증 정보를 확인하고, 인증이 필요한 리소스에 대한 접근을 허용하거나 거부하는 등의 인증 처리를 처리합니다.
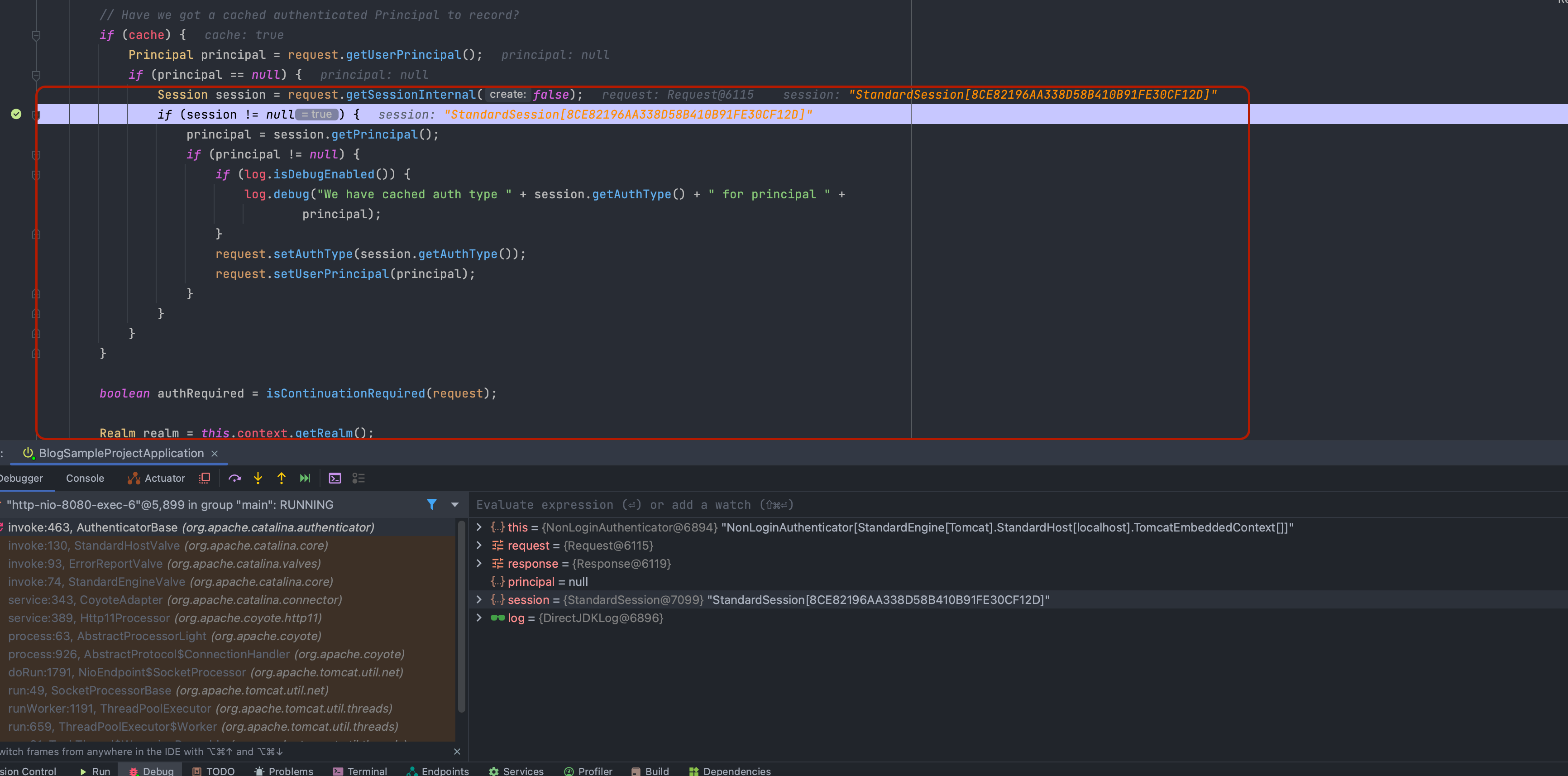
위 과정이 모두 문제 없이 완료된다면, 정상적으로 SampleController에 클라이언트 요청이 정상적으로 도착하여, 추가 로직을 수행할 수 있게 됩니다.
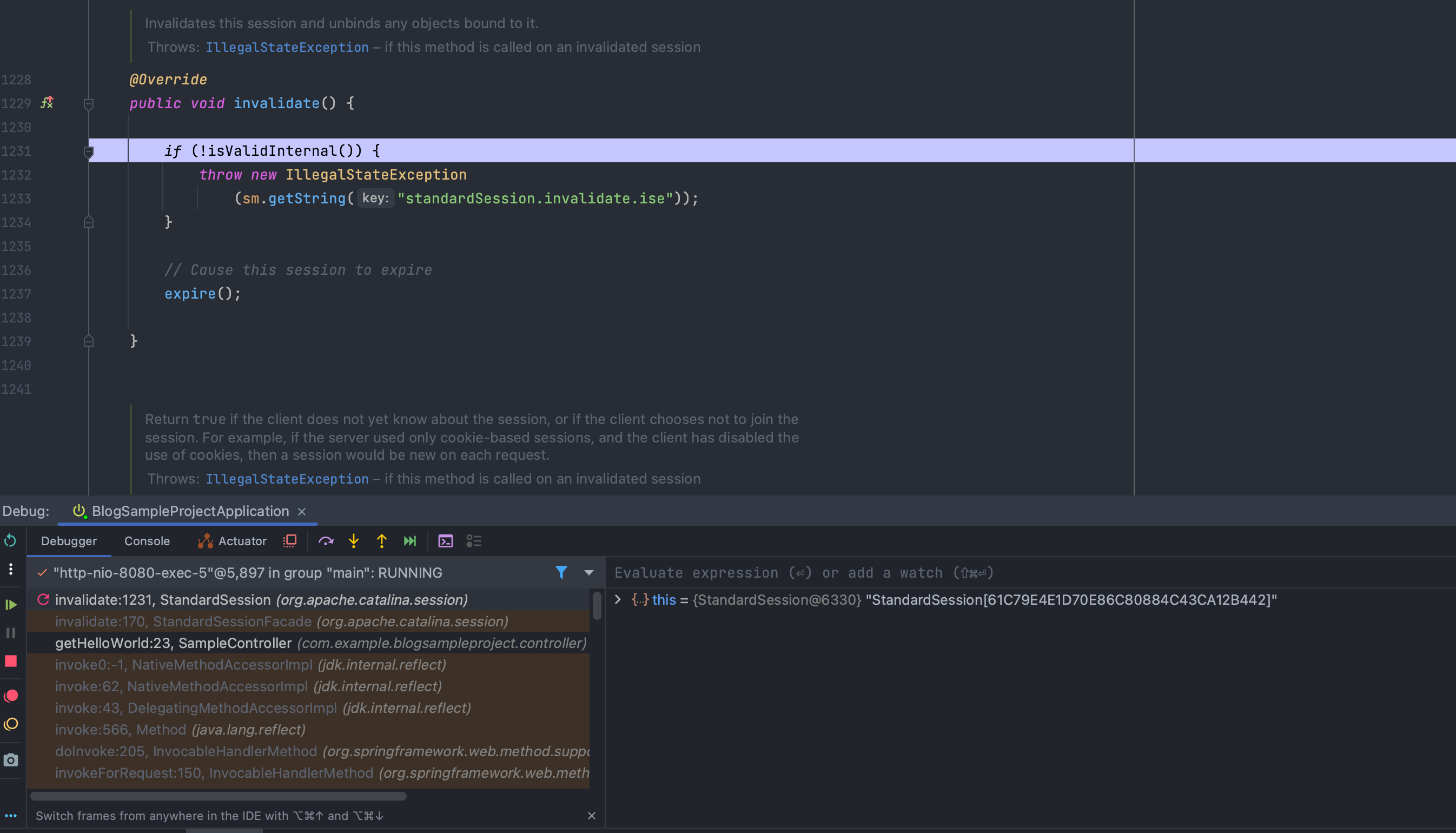
void invalidate
해당 세션 객체를 무효화한 다음, 바인딩 된 모든 객체를 제거합니다.
먼저 invalidate() 메소드에서 유효한 session을 확인 후, 내부의 expire() 메소드를 호출합니다.
그리고 해당 세션 객체를 비활성화 하는데 필요한 내부 처리를 수행합니다.
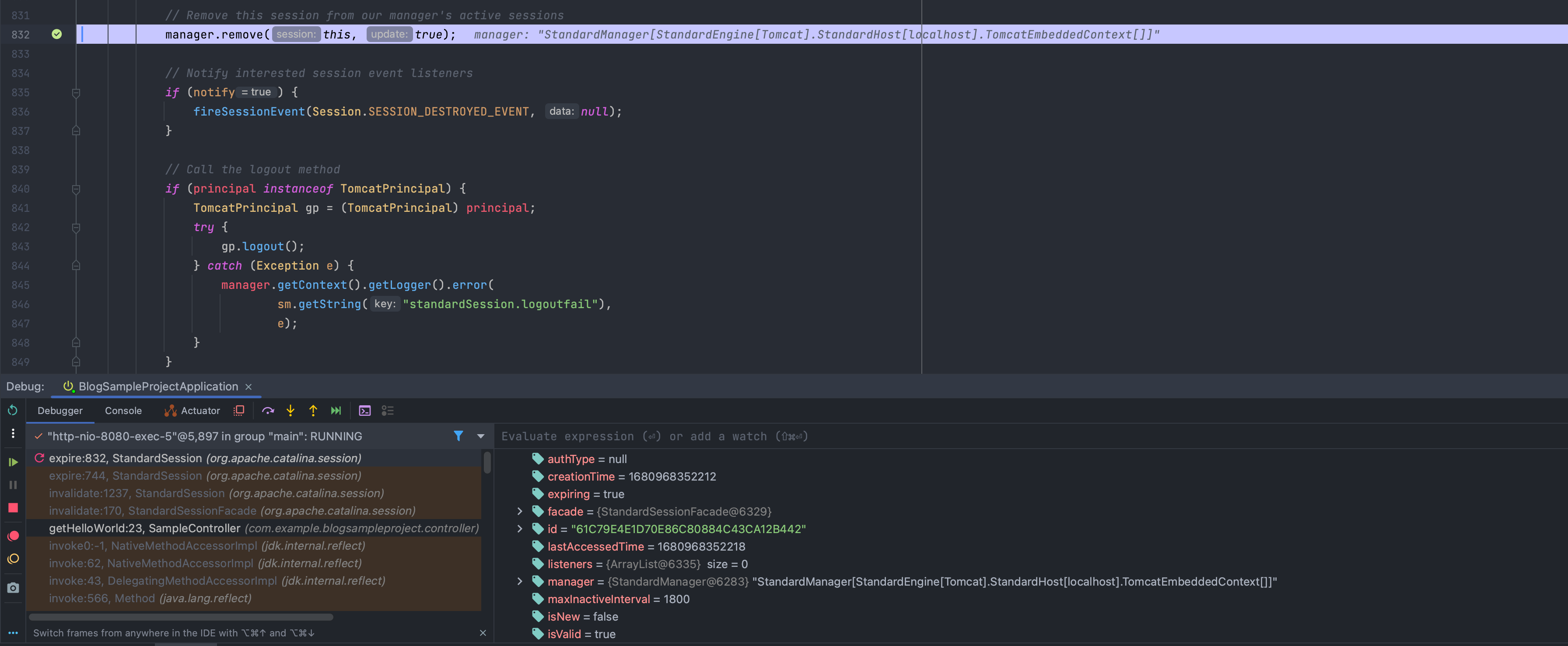
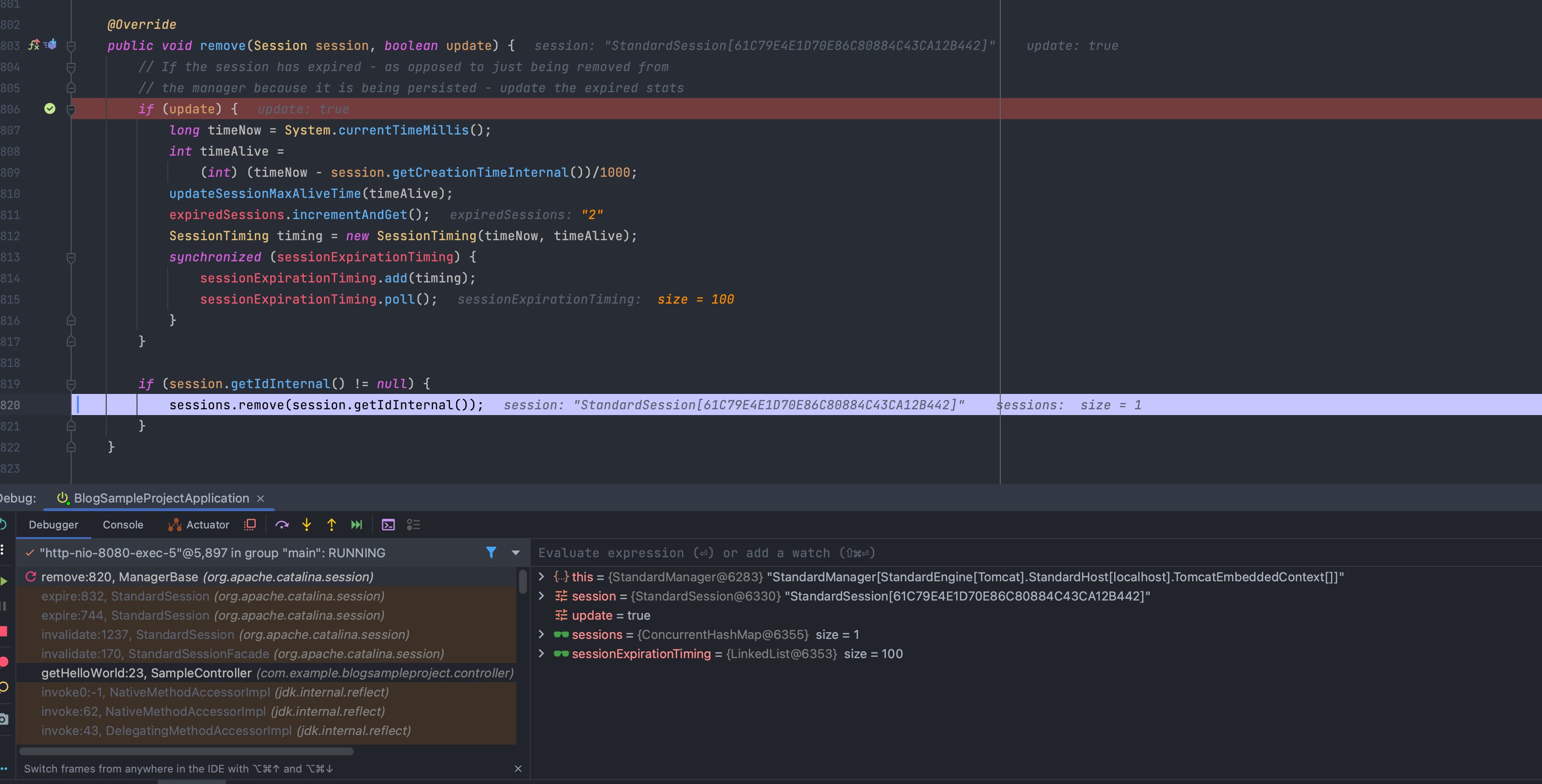
Session 객체들을 관리하는 인터페이스 org.apache.catalina.Manager의 기본 구현체 org.apache.catalina.session.ManagerBase에서 식별된 해당 세션 객체를 제거(remove)합니다.
결과적으로 org.apache.catalina.session.ManagerBase의 sessions의 사이즈는 0이 됩니다.

쿠키(Cookie)
배경
World Wide Web(WWWW)이 초기 단계였던 1994년, 넷스케이프(Netscape Communications Corporation)의 개발자였던 루 몬툴리(Lou Montuli)가 사용자의 컴퓨터에 소량의 데이터를 저장하는 방법으로 쿠키의 개념을 도입했습니다.
쿠키는 웹 사이트 또는 웹 응용 프로그램에 의해 사용자의 장치에 저장되는 작은 텍스트 파일(4KB이하)입니다.
사용자가 웹 사이트를 방문할 때 웹 사이트는 쿠키를 사용자의 브라우저로 보낼 수 있으며, 브라우저는 쿠키를 사용자의 장치에 저장합니다.
특징
- 세션 관리(Session management): 쿠키를 사용하여 웹 사이트의 사용자 세션을 추적할 수 있으므로 사용자는 한 번의 로그인으로 다른 페이지에 액세스할 수 있습니다.
- 개인 설정(Personalization): 쿠키를 사용하여 언어 설정, 글꼴 크기 및 레이아웃 환경 설정과 같은 사용자의 환경을 설정할 수 있습니다.
- 추적(Tracking): 쿠키를 사용하여 웹 사이트에서 사용자가 방문하는 페이지, 사용자가 보는 제품 및 사용자가 수행하는 검색과 같은 사용자의 동작을 추적할 수 있습니다.
장점
- 개인 설정(Personalization): 쿠키를 사용하면 웹 사이트에서 사용자의 기본 설정, 로그인 정보를 기억할 수 있으므로 사용자 환경을 보다 개인화하고 편리하게 만들 수 있습니다.
- 분석(Analytics): 사용자의 웹 사이트 사용에 대한 콘텐츠 및 마케팅 전략을 개선하고 최적화하는 데 도움이 될 수 있습니다.
- 광고(Advertising): 쿠키는 사용자의 행동과 관심사에 따라 표적 광고를 전달하는 데 사용될 수 있으며, 이는 비표적 광고보다 더 효과적일 수 있습니다.
- 전자상 거래(E-commerce): 쿠키는 사용자의 쇼핑 카트에 있는 항목을 기억하고, 개인화된 제품 권장 사항을 만들고, 체크아웃 프로세스를 용이하게 하는 데 사용될 수 있습니다.
단점
- 개인 정보 보호(Privacy concerns): 쿠키를 사용하여 사용자의 행동 및 관심사에 대한 자세한 프로필들이 추적되고 있다는 것을 모르는 경우 개인 정보 보호 문제가 발생할 수 있습니다.
- 보안 위험(Security risks): 쿠키는 사용자의 계정 및 개인 정보를 손상시킬 수 있는 XSS(크로스 사이트 스크립팅) 공격 및 CSRF(크로스 사이트 요청 위조) 공격에 사용될 수 있습니다.
- 쿠키 차단(Cookie blocking): 브라우저 설정에서 쿠키를 차단할 수 있으므로 쿠키에 의존하는 웹 사이트의 기능이 제한될 수 있습니다.
- 구식 기술(Outdated technology): 쿠키는 서버 측 스토리지 및 로컬 스토리지와 같은 최신 기술보다 효율성이 떨어질 수 있는 오래된 기술입니다.
XSS(Cross Site Scripting)와 CSRF(Cross-site request forgery)
XSS: 웹 사이트 관리자가 아닌 이가 웹 페이지에 악성 스크립트를 사입할 수 있는 취약점으로 발생되는 공격입니다.
CSRF: 사용자가 사용자가 자신의 의지와는 무관하게 공격자가 의도한 행위(수정, 삭제, 등록 등)를 특정 웹사이트에 요청하게 하는 공격을 말합니다.
XSS는 공격 대상이 Client, CSRF는 Server입니다.
XSS는 사용자가 특정 웹사이트를 신용하는 점을 노린 것이라면, CSRF는 특정 웹사이트가 사용자의 웹 브라우저를 신용하는 상태를 노린 것입니다.
Spring Framework에서의 Cookie
Spring Framework에서는 javax.servlet.http.Cookie를 활용해서 Cookie를 관리하고 처리합니다.
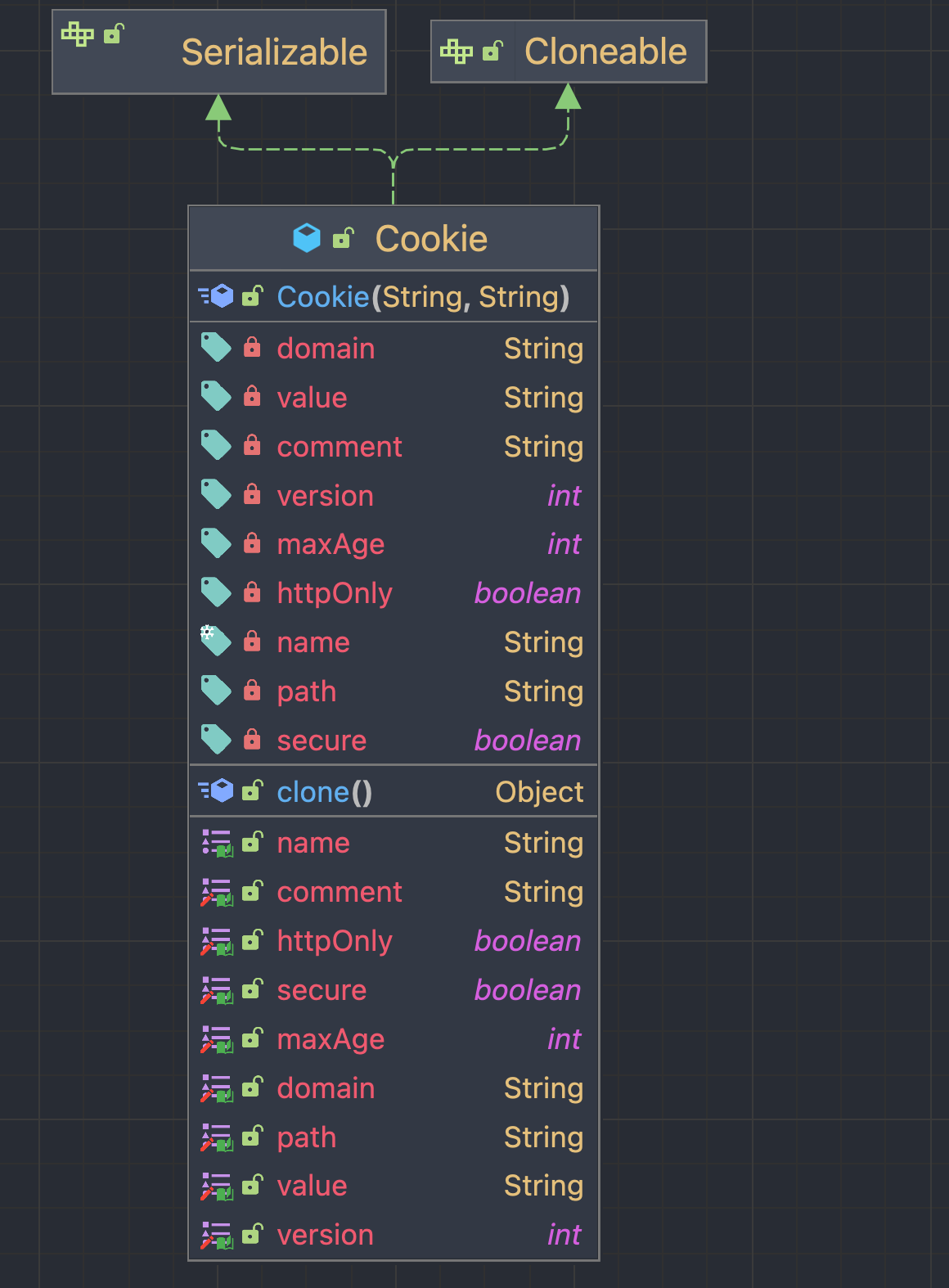
Cookie 객체는 쿠키명과 쿠키 값을 가진 생성자를 통해 생성합니다.
생성된 Cookie 객체는 아래와 같이 다양한 메소드들을 제공하지만 주요 메소드 setMaxAge(), setPath() 만 살펴 보겠습니다.
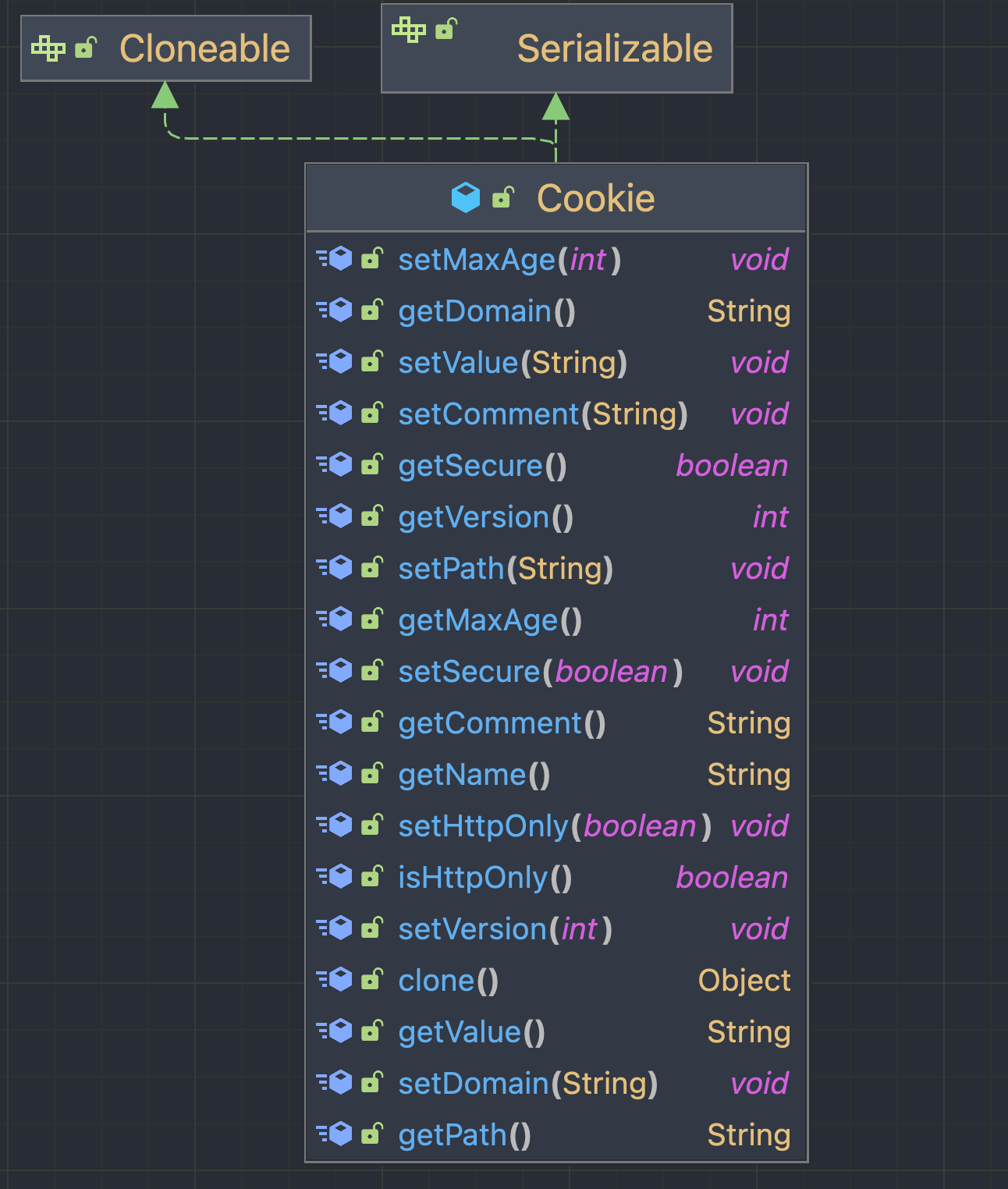
Cookie객체는HttpSession객체에서 제공해주는invalidate와 같은 제거 전용 메소드가 없습니다.
주요 메소드
setMaxAge(int)
쿠키의 최대 사용 기간(초)을 설정합니다. 양수 값은 쿠키가 몇 초 후에 만료됨을 나타냅니다.
음수 값은 쿠키가 영구적으로 저장되지 않으며 웹 브라우저가 종료될 때 삭제됨을 의미합니다.
값이 0이면 쿠키가 삭제됩니다.
setPath(String)
클라이언트가 쿠키를 반환할 쿠키 경로를 지정합니다.
쿠키는 지정한 디렉토리의 모든 페이지와 해당 디렉토리의 하위 디렉토리에 있는 모든 페이지에 표시됩니다. 쿠키 경로에는 쿠키를 설정하는 서블릿이 포함되어야 합니다.
마치며
이렇게 서버에서 보안, 인증, 권한 부여 등을 어떤 방법으로 처리할 수 있는지 확인했습니다.
위에 서술 된 순서는 적용된 역사의 역순으로 작성 되었습니다.
원래 의도한 바는 각각의 방식이 과거 기술의 어떤 부분을 보완하여 사용하였는지를 나타내기 위해 시간적 역순의 형태로 작성했습니다만 의도대로 작성 되었는지에 대해서는 저 스스로에게 의구심이 듭니다.
하지만 각각의 기술들의 등장 배경, 장점, 단점 등을 통해서 좀 더 해당 기술에 대한 특징을 이해하는데 도움이 되길 바랍니다.
오탈자 및 오류 내용을 댓글 또는 메일로 알려주시면, 검토 후 조치하겠습니다.